SQLite
For my music collection - managed under Linux - I had begun to use SQLite as a way to keep track of the music that I had, locate duplicates and files with missing information and generally 'know stuff' about it. Together with all the extra metadata which had been collected - CDDB records, details from 'All Music Guide' for the artist summaries and album reviews, CD cover images from miscellaneous sites, and lyrics from similarly miscellaneous sites - this provided a pretty interesting overview of the collection. I had begun writing a filing system which used this information to present structured content, where the files themselves might live in different locations, and the metadata defined the presented file structure.
SQLite was pretty useful for that - it was small, it didn't need any setup beyond creating tables, and it was pretty efficient. In case anyone reading this doesn't know, SQLite is a file-only (that is, not a server) database system, using the SQL language to query and manipulate data. It is very good at its job - so much so that probably some of the software you are using right now has SQLite built in to it.
I had felt that RISC OS needed a better way to provide storage for quite some time. There are only so many times you can write serialisation code for an in-memory dataset that you need to keep over invocations before you get tired of doing it again. Whilst sometimes you need custom ways to get at data, a lot of the time you just want to store stuff. In the past - back when at University - I had used GDBM which had been supplied with Perl, but this was obviously not reasonable - I had stopped using it once I realised that it was a GNU component, and therefore had the GPL associated with it.
In any case, GDBM isn't that useful for some tasks, as it focuses on key/value pairs. I started looking for other solutions which might fit the requirements:
- Non-restrictive license - GPL was out, LGPL might be acceptable, commercial licenses had to allow redistribution and reuse.
- Efficient on a small system, particularly with low or configurable memory overheads.
- Un-managed solution - setting up users and access permissions wasn't going to work.
- Non-central - using a single instance for storage, like a server would, wasn't going to work if the point was that any application should be able to create and maintain databases of its own.
- Easy to use - it is hard enough getting anything accepted, so any interface had to be easy enough for me to understand and provide an interface for.
- C based, or C++ if its simple enough for CFront - only the C based solutions were going to be able to be made into a module, which would allow it to be used from any part of the system.
- Reentrant - It had to be sufficiently reentrant that it could be used through a polled interface.
With the exception of the latter, SQLite was a very good match. The problem with the reentrancy was that if you perform operations in SVC mode it needs to be able to do a little of the work, then return results or say 'still working'. If the operation might take a couple of minutes, you really don't want to be left stuck in SVC mode with nothing happening - the primary problem with the design of RISC OS. Changing that wasn't going to happen overnight (although as I have mentioned in other rambles, it was coming). So the interface needed to be able to do work in small chunks. SQLite didn't.
However, it used a byte code interpreter to perform its operations, which did retain all the state. It was relatively easy to insert a forced break into the byte code interpreter when a set time limit had been reached and return a result to say that the operation was continuing.
This was all based on SQLite 2.8.10 which was a pretty good. There were quite a few operations that were limited in that version so certain queries produced odd results. A significant amount of work went into the subsequent SQLite 3 version, and the two file formats are not compatible, sadly. If I were to upgrade SQLite, I would be looking at a SQLite 3 with some tied back limitations, and similar restriction on the byte code interpreter - which would be harder, as it has become a lot more complex since then.
It is a little amusing that when I joined Picsel a few years later, one of my first tasks was to work on part of the integration of SQLite with the ePAGE system. Within my current job, a few of the systems that we use (BuildBot and ReviewBoard being typical examples) have SQLite back end storage, so it is quite common to still be using it. Through my time working with it, I've found it to be very occasionally quirky (usually down to the SQL language more than the implementation), the developers to be professional, thorough and incredibly courteous and quick to respond to issues. It is, to me, an excellent example of open source software.
Anyhow, having used SQLite for some things in RISC OS and having built it to work with the standard libraries - a relatively trivial task as the file operations were mostly well abstracted, and locking was effectively performed by the design of FileSwitch - it was time to turn it into a module.
ZLib had not been received so well, partly because of the lack of documentation, and partly because of the more complex API it presented. I didn't want to repeat that, and my initial goal was to have a storage system most developers would be able to get on with. The API I designed intended to reflect this... except that it went a little too far. I tried to make a generic form of interface that could be understood easily, which it could. But the specific use of the interface to perform a SQL operation was harder to decide, and in many cases you would be left calling SWIs 'because that's the way it works', rather than because that was the operation you needed.
I only realised the problems with the API after quite a bit of playing with it, and decided it needed a rework. By then, though, the time I had set aside for experimenting with it had passed and I needed to move on to other things. The module was put on one side and I don't think I returned to it.
MiniSQLite
I created a little tool to operate on the SQLite databases from the command line. Similar to the other 'Mini*' tools that I had written, this was the most cut down that a tool can be whilst still packing in the features that you need to use it. Apparently this MiniSQLite tool was 4236 bytes - which beats even the MiniZip tool, which weighed in at 6336 bytes. (both compressed, obviously)
*MiniSQLite test MiniSQLite 0.00 (27 Apr 2002) Use '.quit' to exit minisqlite> SELECT * FROM sqlite_master; type|name|tbl_name|rootpage|sql table|people|people|3|CREATE TABLE people (name VARCHAR, age VARCHAR) minisqlite> SELECT * FROM people; name|age Justin|27 minisqlite>
DBResultManager
Before SQLite was put on hiatus, though, I had started to work on more generalised functions for accessing databases. My reasoning was again pretty simple (you can argue successfully that I don't think in complex terms!)... SQLite is a storage system, and that's fine - but there are other storage systems already available and which could be available. Tying myself to just SQLite would be silly; some clients might need server based storage, or might want to access a private database, rather than some local stored system.
My answer was to make access to databases more generic still, focusing on the query results. Different data sources could provide query/result interfaces to a manager - DBResultManager - which could be the central query point. You could then have different tools which would be able to pass queries to DBResultManager, and present the results returned, without knowing much more about what they were talking to. Queries would be text strings, to make life easier.
The interface was a little naive, and whilst I had looked at some interfaces in the past I hadn't really done enough research into how the interfaces to the database engines were used to come up with a superset that would be sufficient. If I were doing it now, it would be slightly different - mostly in parameter passing and the naming conventions used.
The SQLite module registered itself as a source with DBResultManager, allowing searches to be performed and results retrieved. A second module was created to try to show that the queries neither needed to be SQL, nor needed to be based on a relational database. The DBResolver module provided a rudimentary interface to retrieve a list of addresses using the Resolver to communicate with DNS.
In the case of DBResolver the 'query' was just the name of the host to look up. The result was a list of attributes retrieved from the Resolver - the address and host name aliases. Whilst it wasn't an exceptionally useful result source, it was a database that could be queried and it was quite different to that provided by SQLite.
Probably it would have been more useful to have the multicast DNS resolver provide results through this interface, but that project had not started when this was being experimented with.
Scrolling List
I had always wanted to provide an automatic way to present the results - which was one reason for trying to abstract the SQLite code away. The most obvious way to present results from a search is through the Scrolling List gadget. The gadget had been extended to provide columns, which made it a lot easier to present the results from any searches.
To integrate the searching with the scrolling list, a 'query' operation was added to the API for the Scrolling List. This allowed the Scrolling List to get all its data from the DBResultManager. The module would use a special mechanism using a new task to send messages to the gadget regularly. These messages would cause the gadget to wake up, and it could then poll the DBResultManager for more data.
As the Scrolling List does not control the application it is running under, it cannot change the poll mask, or update the idle period - that would be the job of Toolbox, and in any case it would not allow the system to provide notifications to the gadget out of band.
It was necessary to know when the query had finally completed, in the case of many results. For example a database query could take a few seconds, during which the results would be populated in the gadget. However to the user a lack of results and a completion would look very similar unless the gadget was changed.
It might seem reasonable to grey the gadget until the operation completed, but that assumes that the query will ever complete. For example, if the query was for (for example) system events (which wasn't a source I had created, but could have been), the query could continue indefinitely. So the control of the gadget's presentation should be left to the application, and that relied on the application knowing when the operation had completed - a new event was created to inform the application.
Normally when you provide a set of options in the results window, these results are actually referenced by some other unique identifier. For example, a list of user names might really be associated with a numeric identifier. However, you might not want to show the identifier. In fact you might not even want to show a user name - you might want to show full names, or even nicknames, depending on the interface required. But despite this, doing the reverse lookup when an item is selected seems redundant, especially as the information has probably just been retrieved.
The simple 'solution' to this was to allow columns to be hidden. This would allow (for example) the user name and identifier to be fetched, but only the user name column displayed. Rather than just flagging that the column was to be hidden, I wanted to make the feature a little more flexible, so instead I added support for setting the widths of the columns - they could be automatically sized, or given an explicit size. Of course the explicit size could be 0, effectively hiding the entire column.
I sent a copy of the updated module, and the Database stack, to a few people to try out and give some feedback. Whilst the feedback was generally positive, Chris Bazley pointed out the glaringly obvious point that such a feature should not be embedded into the Scrolling List. This was pretty obvious, and I didn't really want it to remain there, but it was easy to implement there. It is always useful to have people point out the things that you knew but had forgotten because you'd got too deep in the implementation to step back.
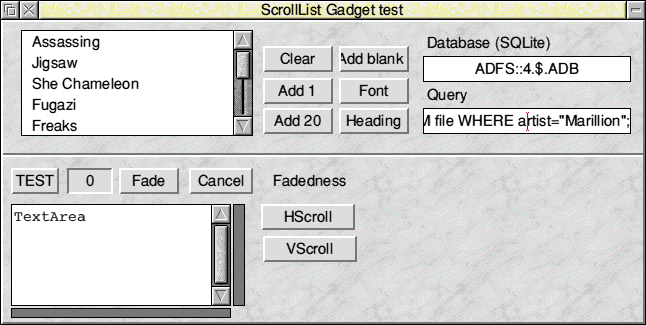
Search was on my music database, using something like:
SELECT album FROM file WHERE artist="Marillion";.
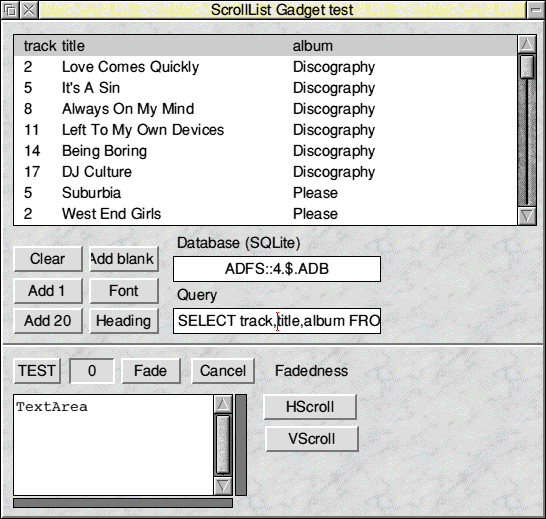
Search was on my music database, using something like:
SELECT track, title, album FROM file WHERE artist="Pet Shop Boys" AND track % 3 == 2;.
The implementation within the Scrolling List was disabled and left that way - it wasn't ready, and since both the DBResultManager and SQLite interfaces needed to be updated, it needed a bit more work to make usable. Moving on to other things, there were still some useful things that came out of the work - the Scrolling List had had a bigger exercise for a start. Because of the number of changes that take place with the Scrolling List due to the results arriving in large batches and then being updated with more on another poll, the column sizing and row calculations had been found to be quite inefficient. These had been improved, which would benefit anyone adding many rows to the Scrolling List manually.
Disclaimer: By submitting comments through this form you are implicitly agreeing to allow its reproduction in the diary.