Mozilla
!StrongHelp has been great for providing useful reference information for the developer community over the years. Where the PRMs were too bulky for a quick reference, !StrongHelp was great.
However, the documentation I was producing was focused on HTML. I saw some unreleased (and very impressive) projects to provide alternative help systems, but they never appeared to move into released states. Additionally, RISC OS was not supplied with a browser (not one that was actually targeted for the system - !Webite, !Webster, and !ArcWeb all existed, and there was the file-only version of !Fresco that had been supplied as part of magazine discs in the past. So, whilst people could obtain a browser, they wouldn't be able to read the documentation that was supplied without doing so.
The Mozilla mini-project was a way to address this - and it was intentionally experimental. The HTML content we were producing was defined to be simple. It wasn't going to use any CSS and, whilst it used tables, it wasn't going to go wild with them (actually the !PRMinXML was a little heavier than the PRMs on tables). As such a 'simple' browser would do.
![]()
!BuildNS
Back when I was at University, along with Doom, one of thieves of my time was
the release of the Mozilla codebase - Mozilla Classic as it is now known.
Armed with an A5000 and UnixLib, I aimed to make as much of Mozilla build as
I could. The goal was never to get a web browser out of it per se, but to
see whether there was anything it provided that could be useful.
In the process, I could learn about
some commercial code which had been seen to be incredibly successful. It did
help a lot in teaching me how 'big' projects worked, and how they had tackled
the issues of creating cross platform code (the XP libs, and the NSPR - Netscape Portable Run-Time).
My version had its own build environment, using Netscape's own
makefiles to construct RISC OS makefiles which used paths and libraries that
it could understand. I remember many frustrations at the time when building,
with components that just refused to build when given one set of options
but worked fine when given others. At one time, the defines in the makefile had
a definition like -define DUMMY=ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ in
the middle, because without it the build just would not work. ![]() This was
due to the constraint on the command line arguments being
smaller than the command line buffer limit expected by the AMU invocation.
If this limit was exceeded, AMU would start to use DDEUtils,
which allowed significantly longer argument strings,
This was
due to the constraint on the command line arguments being
smaller than the command line buffer limit expected by the AMU invocation.
If this limit was exceeded, AMU would start to use DDEUtils,
which allowed significantly longer argument strings,
The problem was that AMU would start
using DDEUtils at about 240 character command lines (I guess - I can't
remember the exact value). The command line would start 'cc <stuff>' and would
be less than 200 characters. However, the cc command needs to be expanded to a
fully specified path name, which on my machine would have probably been something like
ADFS::Hades.$.!Program.C.AcornC.Library.cc (or something
similar - I don't remember exactly where it would have been). The expansion
would push the whole string to longer than the 256 character command line
buffer, so it couldn't be run. Adding in the dummy define caused the
initial command line string to be longer than the threshold, so AMU
changed to using DDEUtils for the arguments instead. ![]() Oh the faff.
Oh the faff.
Oh gosh, there is even a threading implementation in the Mozilla build libraries. I had completely forgotten there was a special one I wrote back then. It looks rudimentary, but functional. I wouldn't dare use it outside a single tasking system, though.
![]() I have just read in the notes that there was a problem with 12 nested
includes when you were using cc. I am pretty certain that this was due
to the fact that there were a limited number of FILE descriptors in the
static workspace and would fail if
you hit that. Having just read the
patch code, I cringe at how evil it is - we replace the C library initialisation,
and after the branch tables have been populated we replace
'
I have just read in the notes that there was a problem with 12 nested
includes when you were using cc. I am pretty certain that this was due
to the fact that there were a limited number of FILE descriptors in the
static workspace and would fail if
you hit that. Having just read the
patch code, I cringe at how evil it is - we replace the C library initialisation,
and after the branch tables have been populated we replace
'fopen' and 'fclose' with calls to our own routines.
When the tool calls 'fopen'
we check whether the operation succeeded - if not, we return. If we did
succeed, we allocate some RMA and copy the FILE descriptor into it. We
then zero the flags word in the original block, effectively freeing it.
The faked file descriptors are closed on shutdown, and we register an
exit handler which will be called to free all the blocks when cc
is done.
Because obviously that is how you get around a limitation in the C
compiler's environment ![]() .
.
How much did I get compiled? According to the FAQ and release notes, about 318 files - although it does say that this is under revision. I am relatively certain that part way through working on it I got distracted by something. Probably coursework, or exams, or something equally unimportant. There were quite a few of the supplied tests working as well, which was great to see - you compile up, make changes to the code and then repeat. Eventually you get out a test program that you can run and it explodes and you repeat some more. All very fun. On an A5000. 25Mhz of sheer processing power. Oh yes, and running in a TaskWindow. A TaskWindow which had been specially modified to run with smaller time-slices so that the desktop was usable, and I could therefore edit code sanely whilst the multi-hour compiles ran.
One of the things that I came across in working with the code taught me a useful lesson - more so than some of the courses that I did, and more than my own experience till than had told me was important. If you are writing something that you think cannot go wrong, but will have bad effects if it does - create a test to show that it cannot go wrong. One comment that has stuck with me so long after the event, but I am always happy to cite it as the perfect reason for unit tests - or any form of testing - to show that what you think you are doing is actually what you are doing.
** This is stupid, but this is the second release where the non-function of
** a simple binary search has turned out to be a bug, and I am tired of it.
************************************************************ * Welcome to Acorn Netscape. Please wait whilst I compile. * * - Sun,24 May 17:55:31 Build: 30 ------------------------ * ************************************************************ dir NSPR: amu jpp Makefile-mk RealMake >> Making LibNSPR jpp Makefile-mk RealMake >> Making LibNSPR Lib-based things jpp Makefile-mk RealMake >> Making NSPR MsgC cc-fopen -DOSTYPE="RISCOS/3.6" -DRISCOS ... ... makealf -o o.libmisc o.bkmutils o.glhist o.undo o.bkmks o.shist o.hotlist Copying object files: 6/6 Building symbol table: 6/6 ******************************************* * Acorn Netscape build finished compiling * * - Mon,25 May 00:50:03 Build: 30 ------- * *******************************************
Quit your whining about things building too slowly ![]() .
.
I clearly wasn't thinking about the future much; I didn't include a year in the date! It was 1998.
![]()
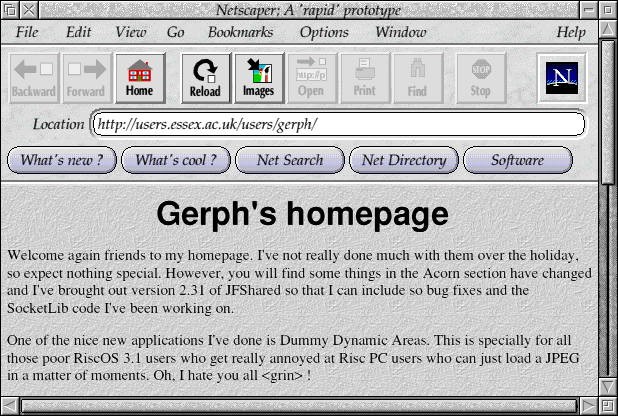
!Netscaper
I also created a fake !Netscaper application that I gave to a couple of people
at a show, just to be vaguely amusing - it was a complete fake
interface which rendered a DrawFile of my website at the time. That
said, the back and forward buttons were hooked up to a history, the
URL bar worked (I think) and would queue a request for fetching - but
wouldn't actually get any data. It amused me at the time.
The little Mozilla project sat around for a few years, unloved. !ArcWeb gained frame support, !Fresco came, !Webster morphed into !WebsterXL, !Browse appeared - looking swish - and then !Oregano appeared - looking very swish but bloated... !Oregano 2 appeared, the obese and slow evolution of the original (it really was very heavy on memory). Peter Naulls ported a few browsers and started on !Firefox. In other words, lots of time passed.
All the browsers had restrictions on them, or were just not suitable - to endorse any one browser was both unfair on the others, and quite against the spirit of RISCOS Ltd (that it should support the developers and I never wanted to step on anyone's toes by closing doors or showing favouritism - I think we did quite well there). Thus it was that many of the components and applications supplied with the Operating System were limited - they would never develop into something that would remove a market for other developers.
So... to go back to the earlier remarks, there needed to be something supplied with the OS which would a) be able to be used for documentation viewing (accepting that it would be 'a browser'), b) could be considered 'small' enough to sit on a playing field with StrongHelp (without replacing it - as !StrongHelp was always going to be many developer's first choice for quick reference material), and c) would not tread on any of the developer's toes.
With this in mind, and the original Mozilla classic source port as a reference, I started again from scratch. UnixLib, upon which I had based the original, was very low in my opinion for a lot of reasons and not really suitable for this port. This time it worked out much better - a few years doing some 'real' development, and more understanding of browsers in general, I 'got' the structure and ported just the bits that I needed.
Starting out with just the HTML parser, and stubbing out functions as necessary, I got a library that I could pipe HTML content into and out would come out token streams. Wow. Not exciting. But then we add in some of Layout as the target for the tokens (I think - I can't remember the actual way that it works without looking at it in a bit more detail) and... now we need a FE; FrontEnd. The initial front end was excellent. It said that all text was 8x8 pixels. It gave the screen size as a fixed size, something like 640x1024, and instead of printing to the screen itself, it produced a program that would do the job. It wrote out a little BASIC program that would produce the page.
MODE MODE
MOVE 264,1008:VDU5:REM <text>
PRINT "heading"
VDU4
MOVE 16,975:DRAW 624,975:REM <hr>
MOVE 16,957:VDU5:REM <text>
PRINT "This is some more stuff. Yay. It seems"
VDU4
MOVE 16,940:VDU5:REM <text>
PRINT "to be working. How's this for a quite"
VDU4
MOVE 16,923:VDU5:REM <text>
PRINT "utterly pointless waste of day. Well,"
VDU4
MOVE 16,906:VDU5:REM <text>
PRINT "a bit longer than a day really. Ok,"
VDU4
MOVE 16,889:VDU5:REM <text>
PRINT "LOT longer than a day. Shall we say a"
VDU4
MOVE 16,872:VDU5:REM <text>
PRINT "couple of months, spread over about 7"
VDU4
MOVE 16,855:VDU5:REM <text>
PRINT "years ? Something like that. Maybe"
VDU4
MOVE 16,838:VDU5:REM <text>
PRINT "longer. "
VDU4
Very tacky! That was 7 March 2004, so... yeah it wasn't the cutting
edge of browsers ![]() . By the 14th I had an application that you
could drop a HTML file on, and it would appear - albeit simply in system
font. According to the description I have got here "No
CSS, no JS, no frames (not tried IFrames), simple colour only,
no images, no fonts, no bullets, only simple table outline
outlines, no off-screen compositing, no deferred layout
processing, no embedded objects."
. By the 14th I had an application that you
could drop a HTML file on, and it would appear - albeit simply in system
font. According to the description I have got here "No
CSS, no JS, no frames (not tried IFrames), simple colour only,
no images, no fonts, no bullets, only simple table outline
outlines, no off-screen compositing, no deferred layout
processing, no embedded objects."
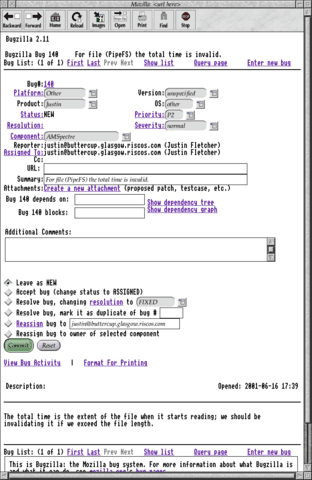
It might all be system font, but the form elements are all proper icons.
(Larger version (32K))
The earliest desktop versions started out using the fake icons I had
created for !Netscaper as its controls (which were mostly non-functional),
used the system font for text rendering. Still, it was
quite obviously a browser.
{kind=link}
Much of the front end handling was pretty rudimentary, and there wasn't much support for anything special - if the window resized it would re-layout, but many of the Toolbox icons would become confused. In particular it is important to note that performing the movement of Toolbox icons as part of the redraw loop is a Bad Idea. Lots of problems came up because of this - mainly because the Mozilla renderer would say (in the redraw loop) 'put/move a control of type x here'. If the controls were form elements, they would be created or moved, because that made sense. However the WindowManager doesn't like that - you shouldn't change the window you are redrawing within the redraw loop. So instead, the calls were queued to be applied after the redraw. That might mean that we ended up with additional redraws because the icon move revealed other text, but it meant that the standard way of working could continue.
An alternative might have been to render to a sprite and use that as the window content, moving it around as the window scrolled. This would be closer to the model that Mozilla expected, but would have used a lot more memory and required a little more management of the off-screen buffers. It also would have reduced any gains that might be made from acceleration (not that we had any yet).
On the 24th it got checked in to source control as a project that might be useful after all. By then we had got form elements (non-functional), fonts, image placeholders, 3D borders, a status bar and progress bar, much better redraw control, 'Find in page' working, links on the page working and URLs could be entered into the address bar and they would load.

Drobe renders relatively well - still a few spacers that are
wrong, but no big deal.
(Larger version (141K))
On the 28th, client-side image maps worked, and many of the layout issues
had been fixed. Frames now work, and we had even got <blink> support (yeah,
really!).
{kind=link}
Over the next week and a half a whole bunch of other little things were fixed and features added, to the point where it became a usable application. It was still a bit slow, but it did do the job.
As part of the tidying up, I needed to backport a chunk of the layout engine which didn't support re-layout well at all. Since re-layout would be common on RISC OS, as you regularly resize windows, it was vital that this did not break. In particular there were a few attributes that got lost during the re-layout process which meant that some elements suddenly moved when you resized the window and would never return to their correct location. Backporting the last C-version of the layout engine before they moved to Gecko was relatively easy, as there wasn't much else that had changed, but this made the layout system work sensibly. It is possible that Gecko could have been worked into the system but its reliance on other components and the hindrance of being C++ would have made this difficult to say the least.
Mozilla Classic was a good choice for a lot of this, because it was C code - which made it much faster than the later C++ version would have been (CFront was not great, or just plain wouldn't work with its source) - and because it didn't try to do everything. It had got basic CSS styling, but it was all implemented through the JavaScript styling that Mozilla had started out with. I had some of the code working that did bits of the style handling in the Style library, but it wasn't really practical and there was never any intention of putting JavaScript into this Mozilla - you do not need it for the plain document viewing that I wanted to do.
Whilst this was a browser that could work on live sites (and because it used the URL Fetcher modules, it worked with whatever those streams gave), it wasn't really a good experience, unfortunately. It might have been unfortunate, but it was never part of the goal to create a general browser.
I began writing the support for plug-ins. The initial implementation was a plug-in itself. That is, Mozilla could be embedded as a plug-in within another browser. It worked really quite well with !Browse. !Fresco seemed to not even want to let you use HTML as a content type for a plug-in, so you couldn't embed it the way that I intended. !Oregano was different though - it spotted that the embedded content was HTML and just rendered the body itself (which was quite neat, but didn't help me).
Part of the idea for this was that you could have a 'stub' plug-in controller which could have the browser inside it. The stub part might be a common implementation such as a Toolbox Object, which would then open up the ability for many more applications. It would be able to provide some form of rendered content without each application having to reinvent it themselves.
Obviously, it would also let applications embed other plug-ins in themselves as a side effect. The Toolbox Object was started, but I got dragged in other directions, and it was never finished. I started the plug-in controlling part of Mozilla itself, but it was embryonic - although it shared a lot of the code for the plug-in client, it was still quite complicated to get in.
I had written plug-in clients a few times before. I wrote !DrawPlug initially, and made !AMSpectre into a plug-in before creating a neat SVG plug-in. The !AMSpectre plug-in supported all sorts of cool AMPlayer bits and renderings so that you could build your MP3 player inside your browser.
AMFiler
!AMFiler
After I had done a lot of work on AMPlayer, I wanted a jukebox to play music with it. Ideally, something network connected that could have a lot of storage and a nice simple interface so that I could pick and play my music. There were a number of solutions around, and Robin Watts had already suggested the SliMP3 system. But I wanted something I could tinker with. I had already written !AMSpectre, a simple frequency band display for the MP3 data in AMPlayer.
![]()
!AMSpectre
It wasn't really a frequency decode - it actually took the decoded frequency bands
from AMPlayer and showed them as little bars. It would therefore be a
little skewed from a proper frequency transform (due to the psychoacoustic modelling which MP3 encoders applied), but not by enough that
you would be that bothered, and it was essentially 'free' data from the decoder.
I have a feeling that the code that populates the bars is a little bit
of assembler that writes directly to the sprite. Yup, the Plotter would
assemble a little bit of code that did all the bars, averaged from the
left and right arrays from AMPlayer. There are some slightly unrolled
loops in it, but from the look of things I wasn't paying attention to
the condition codes - or even what was being done - in those loops.
There is one instruction per iteration that looks like it is pointless,
and a condition code missing on an LDR which means it will underflow the
start of the array, which might be dangerous.
; r8 is the colour array for each height
; r7 is the sprite data position
; width% is the width of the sprite
; r11 is the background colour, placed every 3rd pixel
1070.lineloop
1080 LDR r6,[r8,r5,LSL #2]
1100 STR r6,[r7],#width%
1110 SUBS r5,r5,#1
1120 LDR r6,[r8,r5,LSL #2] ; should be conditional
1140 STRPL r6,[r7],#width%
1150 SUBPLS r5,r5,#1
1160 LDR r6,[r8,r5,LSL #2] ; pointless instruction
1180 STRPL r11,[r7],#width%
1190 SUBPLS r5,r5,#1
1200 BPL lineloop
Ah, how fun ARM can be (and how bad my code can be!).
Anyhow, it looked pretty enough in its little window, but it could be more. It could be a plug-in. I created a simple browser plug-in, initially just for the main spectrum, because that was the main part of !AMSpectre. You could specify the spectrum in a lump of HTML in the browser:
<object type="audio/mpeg" data="thing.t" width=128 height=128>
<param name="Type" value="spectre">
Some text to show if the plug-in isn't there. Or more markup.
</object>
It really wasn't too hard to create the plug-in - I had already done the SVG plug-in and the !DrawPlug plug-in before that. Most of the real handling for the operations was in a library, so I just had to provide a few simple functions like the rendering and message passing.
Once that all worked, I added some little vu-bars for the left and right
channels, and had some little tests working. I then added some very
simple text, so that you could display information from the playing
song - most of the information from AMPlayer was
available. All of the
text fields could take the colours of the text, font name and alignment,
and for extra bonus credit they could have an 'OnClick' action specified,
which would be a command to run when the item was selected. Only a few
commands were supported though - Play, Pause, Toggle Play/Pause, and
Launch URL. The URL could be specially formatted though, so you could
pass the parameters about the track to it.
Although it was useful to be able to specify that you wanted a single
field displayed, that wasn't always very nice. For example, for some
tracks you might not have a track number, so you didn't really want a
field that was just empty all the time. So, I created format strings.
Nothing clever, and it seems like a bit of an odd format now. The
format string could take and of the field names surrounded by $ to
be substituted. So "Title is $track$" would expand to (for example)
"Title is How Soon Is Now". I also added conditional expansions as
well, and the !Help file gives the unreadable example of:
"$track\{$$track$$|$$leaf$$}$" which means show the track
name if there is one, but if not, use the leaf name.
It is all a bit obscure, but it did work for what I wanted. I started laying our lots of components in the browser to make an interface that I liked. I wasn't completely sure what I wanted but I came up with something that was interesting enough.
I had a little module called ControlAMPlayer (which I mentioned in the earlier rambles) which did a lot of the heavy lifting of making sure there was always music playing - it would queue the 'next' track if a new track started. This is where 'next' means the next one along in the directory, or the next one down a directory if you've reached a directory, or the next one in the parent directory if you've reached the end of the directory (and so on until it finds an MP3). It also had the ability to control the player through the keyboard, so keypad +/- were volume controls, * paused, / skipped to the next track, 4/6 were rewind and fast forward. Oh, and Enter opened the directory viewer for the place where the current track was playing.
Double-clicking an MP3 with shift held would queue the track to be
played. I'm pretty sure that ctrl-double-click was 'play track in a
new AMPlayer instance', too which was really neat. Essentially, you would
be thinking of another track, so you would open the window on
the track that is currently playing by pressing Enter, then navigate to the
other track, pause what's playing, ctrl-click the other track and
you could listen to it. Then un-pause the original when you were done,
continuing where you left off. Or you could just leave them both
to play over the top of one another... just because you could doesn't
mean it is a grand idea ![]() .
.
I digress, but it shows one little thing that was missing from the !AMSpectre plug-in implementation. You couldn't pick tracks. For a jukebox that is a pretty fundamental limitation. I had written a 'Filer' library some time previously, for a different project (actually I think I wrote it for a WAD selector for Doom, or the !IRCFaces tool, but anyhow...) so I hooked that up in a little program - !AMFiler - with a redraw handler which showed the names of files, or the ID3 data from the files. Initially, the application only did regular filer type windows - you could open multiple viewers, just like Filer, or you could have them close behind you, replacing the view you had. They resized properly and, more importantly, they had a keyboard controlled focus.
It also maintained a 'playlist' of tracks, so (assuming ControlAMPlayer wasn't doing the same) you could queue up a list of tracks, and then let it play them all one after another. You could always play tracks directly as well.
Once that was all working, I dumped the Plugin library into it, and
made !AMFiler another kind of browser plug-in object. This caused a few little
changes around and about, because the Plugin library expected to control
a window, and the Filer library did too. Also the Filer library never
expected to grow beyond the size that it controlled. Aside from the
final row, it didn't expect dead space - as would happen if your object
in the browser was significantly larger than the size of the Filer
window otherwise. With those two changes made, it just needed a few
changes to the window colour - those 'new' 24bit colour specifiers were used
there, I believe.
I cannot seem to even find the !AMFiler source - it isn't under source control, so this is all from memory (so I reserve the right to be more wrong than usual). I found an old screenshot that I have of the Filer part running outside of the plug-in environment.
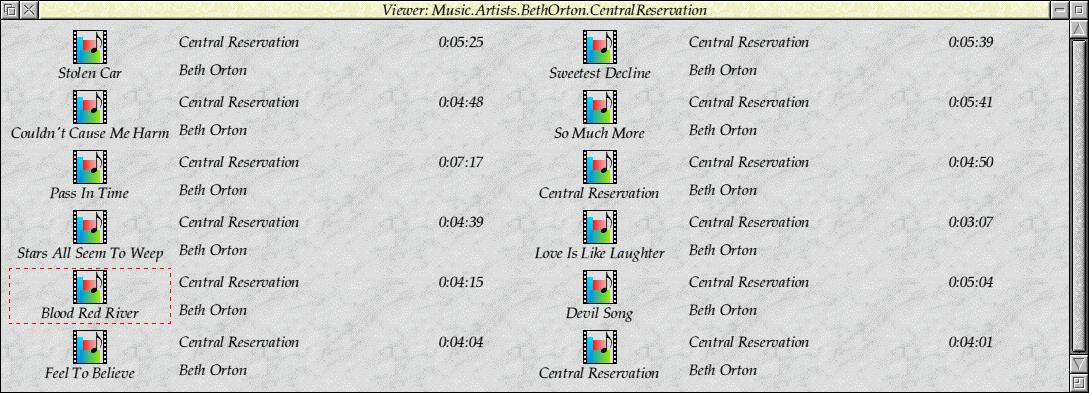
Once running embedded in the browser it looked pretty decent. There was one odd thing in that I had retained the title bar and scrollbars in order that you could show what directory and mode you were in (for example 'playlist'), and so that it was obvious how far through a directory you had scrolled. Only they did not fit at all with the style of jukebox I had created - I was running (I think) Browse in full screen mode, so there wasn't any other furniture around.
Simple solution - create some ToolSprites that follow the style of the jukebox. A red-ish bar for the titlebar, and a rounded blue bar for the scrollbar, and problem solved. This is why I write code and I'm not a designer. I recognise this, which is also why I did this all in the form of a pair of browser plug-ins - someone else better than me might make it look a lot better!
It was displayed at a few shows - I think it was pretty neat - but nothing more than that. I didn't have any screenshots of it running or anything like that - but I found that The Iconbar has a show report from 2002 which has a mention of the player (although I never really thought of it as LCARS like - I can see the similarity though).
Much digging later, I finally found where all the bits were - it had been archived away inside a backup. So I managed to run it and capture a shot of it running...
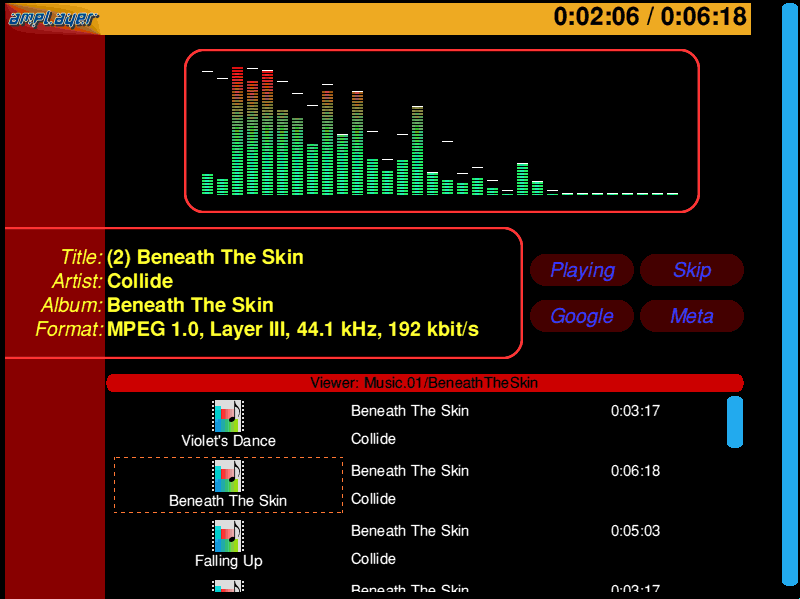
(Animated version (167K))
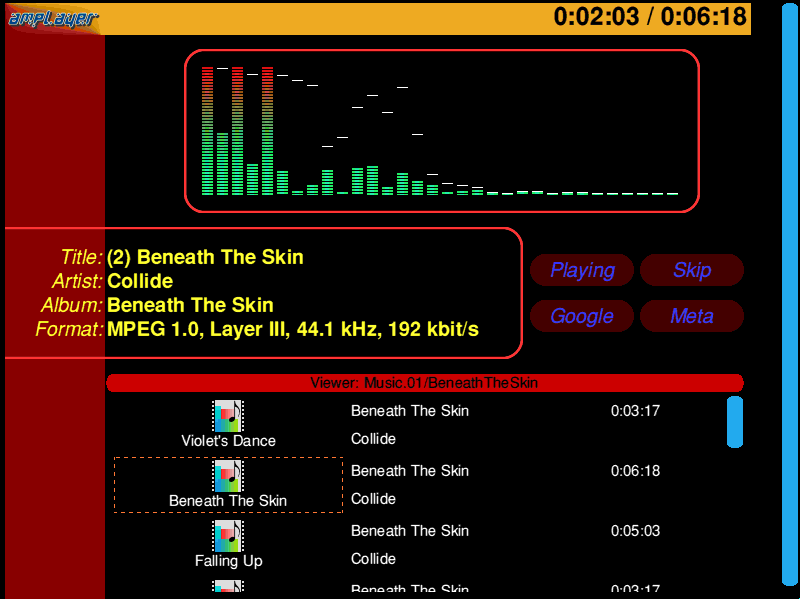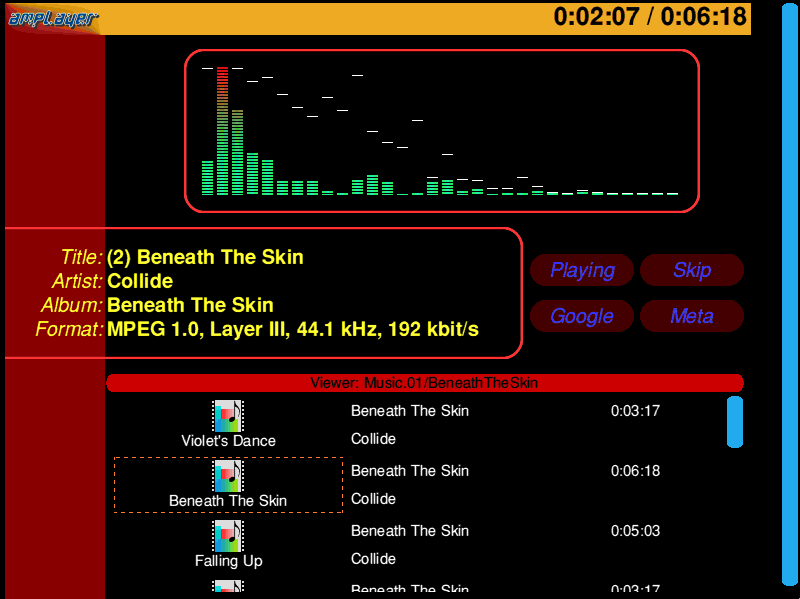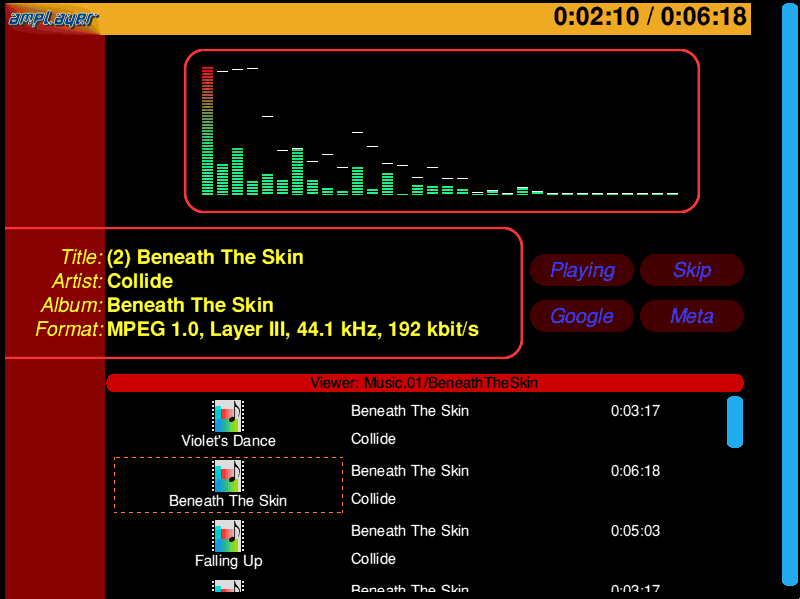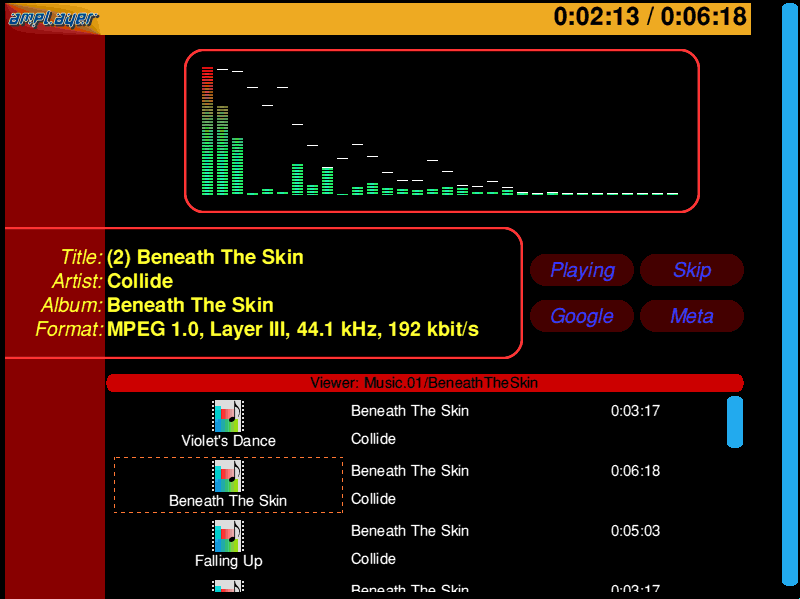{kind=link}
I had really wanted to find someone who thought it worth taking on, but I never really knew what it is that I wanted to do with it beyond that.
Disclaimer: By submitting comments through this form you are implicitly agreeing to allow its reproduction in the diary.