WarGames
I loved the film 'WarGames' when I was little. It is still a pretty cool film, even now. So one
of the early BBC games I wrote was GTNW - 'Global Thermo-Nuclear War' - a
simple two player, turn based, game where you launch nukes at the other
country's cities. Meanwhile they are doing the same to you. All based around
mode 7, and with no fancy graphics at all, it lost of lot of the excitement
of the main war room in the film. But it was fun. It is lost now - I don't think
I ever recovered a copy from the tapes it was on, or if I did, it never
made it from the floppies to the archives. ![]() Oh well.
Oh well.
So when Defcon came out, I bought a copy pretty sharpish. I am pretty sure I bought it before it was out and waited for the unlock on Steam. It was great fun, and even just leaving it running in the spectator mode whilst other people blew one another to radioactive slime was fun.
It made me want to create my own. I knew I would never manage it, because other things would get in the way, but it was interesting to look at. Initially, I wanted to get maps drawn. That isn't so bad; map data for the world can be found in a whole host of places, and I had previously found some good data that I had used elsewhere. It needed reducing so that it wasn't quite as detailed as it had started out. As I intended to draw the maps using either the Draw module, or plain line operations, I wanted to keep the maps limited. In any case, Defcon had had pretty rudimentary maps, and was the better for it.
I collected data and then reduced it - a simple BASIC program would take the data from the 'World Data Bank' map data files, and reduced them to simpler versions. Differing levels of quality could be generated so that the maps could be viewed with different levels of detail depending on the zoom level. The resulting files reduced 7MB of map data down to about 65K at the highest detail level. The program could produce more accurate maps from the data, but the benefit visually at the levels I was expecting would not really be worth it.
As well as reducing the quality, it would also join together sections that had been disjoint in the original data, which made for longer paths. Longer paths would be more efficient when passed to the Draw module for rendering, up to a limit. This also meant reversing paths some of the time, as the paths weren't always ordered in the same way.
Having got the data, I wanted to plot it. Plotting maps is interesting.
There are so many different ways to render a globe on a 2 dimensional plane,
each with their own advantages and disadvantages. Finding different
projections for the maps was far more fun than doing other things like
actually implementing parts of the game ![]() .
.
I wrote little routines - very simply, because in general it isn't that hard for some of the projections - to handle the different projections. According to the code I can see here, I had written the simple transforms for:
- Linear (Equirectangular)
- Mercator
- Lambert cylindrical equal area projection
- Orthographic projection
- Azimuthal equidistant projection
- Sinusoidal projection
- Peter's projection
- Polyconic
Not all worked, because in some cases I couldn't get the code right on some, and I'm not sure exactly how to make them work now, because there are no notes on how it works, sadly. I could work it out given time, but I'm not that fussed right now.
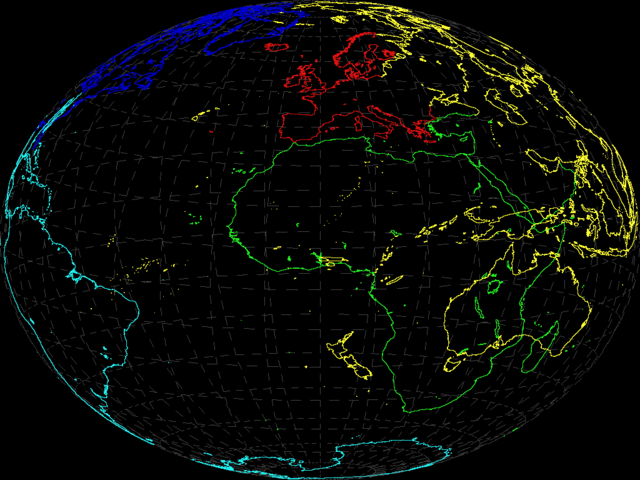
(Larger version (46K))
{kind=link}
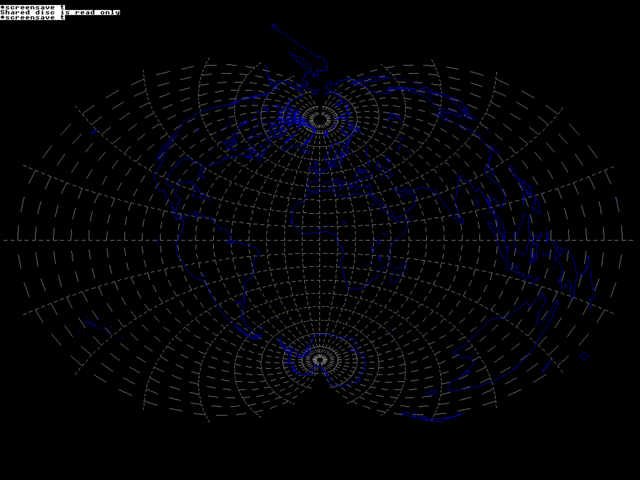
(Larger version (32K))
{kind=link}
Having got the map plotted, I used a bunch of city location data, together with their populations to calculate nearest neighbour countries automatically. That was just a small Perl program that constructed a bunch of data to be compiled into the C code directly. Plotting the cities on the map using a logarithmic scale for the population size so that the huge cities didn't become massive blobs, and the small cities were still visible wasn't so hard. Their positions just used the same projection, so it wasn't that complex to place them on the map.
Generating the alliances was more fun. I didn't want to start out with "Europe versus America" and the like, as Defcon had done. The original WarGames had lots of interesting little scenarios where different groups were aligned. I set out to randomly allocate core groups, and then grow those groups by their neighbours, but with a random possibility that a remaining country could align itself with a group. The result was that, mostly, you had alliances grouped geographically, but you could often have the odd group of countries across the globe aligning themselves with a larger faction elsewhere.
The whole lot was plotted by cities coloured according to the alliance they were in using the configured map projection. It looked pretty neat - but I don't have any screenshots, and haven't worked out how to use it.
With the alliances working, I started on missile path projections for arbitrary source and destination. Actually, the source and destinations were just cities because those positions were far easier to pull from the database, but once out of the database they were mostly arbitrary. The problem with the missile paths is that they both had to look decent, and they had to incorporate a height component which was completely missing from the projections.
In Defcon, they opted mostly for just making the missiles go 'up' toward the top of the screen, even in the southern hemisphere. This introduced interesting strategic effects, which you had to be aware of when playing. I wasn't really sure which I preferred - as I had gone for accuracy with positioning and projections, it would make sense to make the missiles appear to travel accurately as well. Anyhow, I tried a few things and wasn't happy with any of them really. Nor was I happy with my shortest path calculations. I needed to go back to the maths at some point and work it out differently, because I was just getting it wrong. Missile paths would avoid the poles, despite there being a more direct route over them, and sometimes would go the "wrong way" around the world, rather than taking the shortest path.
Aside from being very happy with the maps and city details - and showing them off to Mum and Dad, like a little kid - there wasn't much else to show for the time spent on it. It was a happy distraction, and as a real manipulation of data, it reminded me a lot of when I used to do that kind of thing back at school.
But ultimately it wasn't useful. Oh well.
Spread Sheet
I wanted to create a Toolbox gadget which could be used to display tables of data. I had started to do this with the Scrolling List Gadget, but it wasn't particularly good for general use. Particularly, cells weren't directly addressable, and updating rows or cells was not at all friendly. I began to write a very simple grid library that I could use for the gadget, but rapidly found myself distracted into making the grid more controllable.
Every cell should be able to be displayed in distinct ways, using styles, and with alignments and numerical formats. That was the idea, anyhow; about half of it got implemented, but it was working pretty well. Having got the basics of cell manipulation and storage working, I added functions to provide range and cell references.
I decided, almost in passing, to create a spreadsheet library from the code
that I'd created. To make it flexible and powerful, I wrapped the library
into JavaScript objects. The idea being that either simple operations be
applied using a common spreadsheet syntax, or they could be performed in a
more scripted manner using JavaScript. Cells could be referenced directly (for example,
Cell['A5']), or through ranges, (for example, Range.A5A8.sum).
Each of the cells would keep track of those it affected, which gave a fast way of recalculating the entire table, and to detect recursive references. Memory was tracked for each sheet individually, which meant that multiple independent sheets could be used at once without (hopefully) affecting one another.
Unlike some of the other projects, this one didn't go anywhere useful. The library was all working quite well, and the interaction with the JavaScript interpreter was actually pretty well controlled. Unlike the other projects, which happened when I had something definite in mind, this one meandered and became much more complex than I had initially intended. Additionally, I was using the project as a small intermediary project to be worked on in breaks whilst I was doing the 32 bit work. As the 32 bit work was itself quite interesting, and covered a huge amount of ground, I spent less time on the spread sheet component.
Calendar
In a similar vein, I wanted a calendar Toolbox Gadget. At the very least it should be a gadget that allowed the selection of a date and time, and was able to highlight events on that date. It is not a lot to ask for, and so I began to write some simple libraries for it. The core handling of the calendar was based around dates, and - as I didn't want a lot of complexity - I supported only the 'simple' western calendar, allowing for leap years. The main use case I expected for it would be for scheduling events, or recording a few (recent) historical details, so this limitation was not a problem for me.
A calendar structure could be populated with text to display within the calendar cells, and a style. The style allowed the cells to have different fonts, colours and borders - the basic structure of the tables was going to be shared with the spread sheet, if the projects progressed. Many of the operations of the calendar and the spread sheet, when it came to the rendering, were very similar.
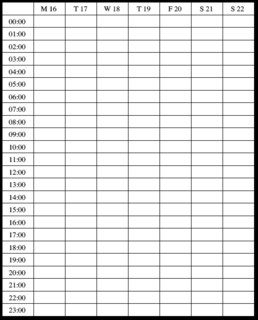
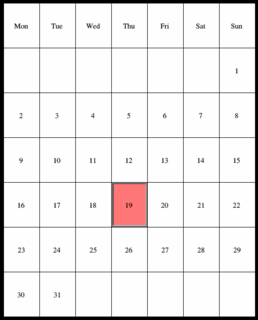
There was a simple rendering library that could draw the calendar data in a number of ways - a day view (which broke down events by hour), a week view (which used the same hourly breakdown, but used seven columns instead of just one), a month view (which showed the dates in a month, laid out in a weekly grid), and a year view (which showed all the months in columns, with the dates lined up with their week days).

Hourly list.
(Larger version (5251))
{kind=link}
Hourly list for a week.
(Larger version (6725))
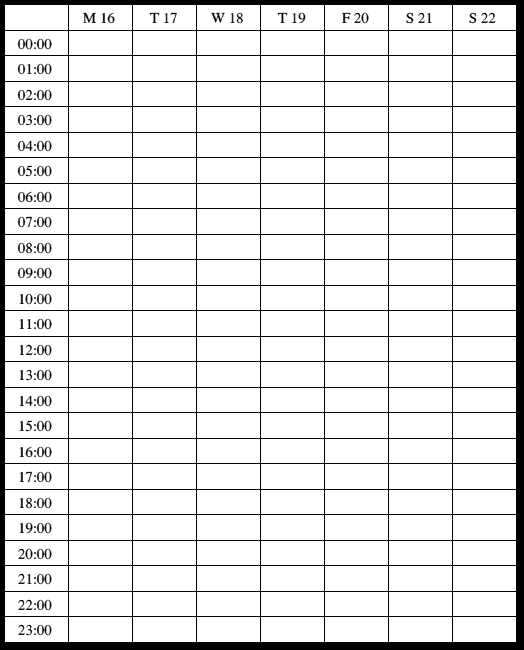{kind=link}
Days in a week.
(Larger version (6554))
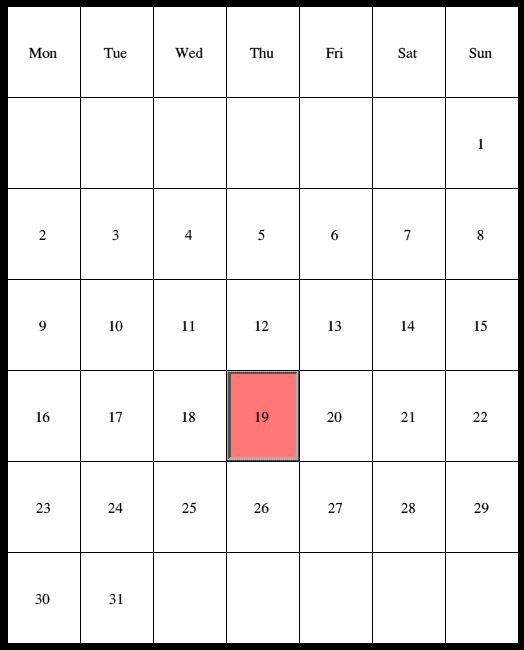{kind=link}
Every day in the year.
(Larger version (17K))
{kind=link}
It's really not all that exciting, but at least it worked. The back end graphics handling was taken from the earlier WMF work (which was also used in the Teletext implementation), which meant that it could be updated to output other formats in the future, such as DrawFile or SVG. Although I wanted to be able to use the library to be used as a Toolbox gadget, it would be useful to be able to print the output, or to export it as a DrawFile.
Threading
Later versions of RISC OS were going to have a significantly different process model, with a different form of environment handlers. Part of the work would need to introduce threading, as some of the inter-process handling would need to block and use mutexes in much the same way as threading within a single process would work. I wanted to get some working experience of implementing and using threading, before it needed to be used more widely within the system.
I implemented a simple threading library which used only known system calls and no Operating System specific knowledge in order to function. The idea was to use the 'POSIX threads' ('Pthreads') calls to provide an implementation that could be used by APCS compliant routines. Despite this, the code was not intended to be used as a library - it would eventually become a part of the core system.
Whilst it was possible to use the main API calls to implement the semaphores, mutexes and thread operations, it was also a requirement that the standard RISC OS mechanisms for yielding and sleeping work; essentially SWI OS_UpCall 6 should be able to be used to yield, waiting on a pollword change. This would allow system calls which used this mechanism to be used completely transparently within the threaded environment.
Internet Socket operations used these calls, when flagged by a special
Socket ioctl call ('FIOSLEEPTW'), when they would
have blocked. This allowed socket operations to work within a TaskWindow, but
under the threaded environment they triggered an explicit thread switch,
waiting on the supplied pollword. To test this, I used a simple Internet service which
listened on a port, and for each connection spawned a new thread. Each
thread would then run independently, waking up as data arrived.
The test worked reasonably well, despite the fact that in order to do the job you need to copy and restore the SVC stack contents when such calls were made. I made no attempt to change the behaviour of the key input or stream output, as these could be quite difficult to work with - and would need changing significantly in the future.
All the environment handlers were trapped, and special entry points used for them. Aborting threads would raise signals in a controlled way, as would the handling of the Escape key. If a backtrace was required, a trace would be performed for each thread, stepping into the preserved SVC stack if necessary. There were special stubs in place for entry points like the implicit SVC mode preemption, and the various yield and sleep operations.
The backtrace code was an early version of the handling that was later used as part of the DiagnosticDump module, and the associated BTSDump tool. Many of the later features of the tool (such as tracing from memory that is not mapped to its logical location) began their life within the threading test code.
There were a few hoops that had to be jumped through to ensure that the Event handler worked as expected - there was a known bug with the WindowManager which meant that there was a small window of opportunity where Events might be triggered whilst the WindowManager had not put the application Event handler in place but the memory for the application was paged out. The result being that if you were using a network heavy background tool and an application had its Event handler in application space, it could crash during the task switch. This was invariably fatal.
The bug is known, but not encountered often because generally you use the SharedCLibrary, so the handler would be in RMA - if you used ANSILib you might find the same problem, and the third party UnixLib encountered it. Part of the problem is in assuming that you can handle events within an application's environment handler. There are very few cases where you can reliably handle events in an application's environment handler, since it is recommended that applications be able to be run within a TaskWindow or as Tasks themselves. Expecting otherwise really only applies to applications that can, and will only, run prior to the desktop start up.
Similarly, trapping the core library calls such that they were not
interrupted was important - the malloc, free and
related calls are not thread safe, so need to be made so. Fortunately, there
is an easy way to ensure that they are not handled badly. The
_interrupts_off symbol is set over these functions, which
can be checked so that we do not preempt during those unsafe operations. I
wrote some handy patching veneers to allow code to be patched to make
unsafe calls safe, but they were not needed for any of the code I expected
to use.
The system worked pretty well, although this was before I introduced the PBTS handling, so it didn't know about some parts of the SVC stack that it would have needed to. Whilst I would have liked to use some of it, the goal was to get a good feel for how preemption would work and how far you could expect it to go. In that regard it worked reasonably well. I had overcome a number of stumbling blocks, and found a few limitations that would need to be addressed - mostly because the system that was being preempted was not expecting to be.
Pascal
When I was at University, my final year project was a decompiler - it took compiled Pascal code and turned it into Pascal source (or to C source, because once you've worked out what the code is doing, it's pretty easy to write the same thing in another language). I used the Norcroft Pascal compiler to create the executables. It was a little old, and not at all supported, but it was the principles of decompilation that I was showing so that didn't matter.
I had a reasonable understanding of Pascal, and I had done work with it during A-Levels as well - although I had forgotten that before I began researching for these rambles. It is very useful to be able to write things in multiple languages. Saying "I'm a C programmer" (or insert other languages) is not really a useful skill when the problems you encounter may be far more suitable for other languages - or they might need to reuse libraries written in another language.
There are compilers for numerous languages out there, some of which are open source, some of which target ARM, and some of which are actually useful. The combination of those three requirements is a little limiting. I looked at the Amsterdam Compiler Kit ('ACK'), as it was quite flexible and supported a number of languages. However, it would require quite a bit of work to make run sensibly, and it was designed as a complete solution, with its own linker and tools.
I looked at other languages as well. BASIC replacements like Bywater BASIC ('bwBASIC') which was limited but provided a reasonable starting point to make some interesting additions, without relying on the quite powerful, but limited BBC BASIC, written in ARM. BwBASIC wasn't ever going to be a great system to use, but it allowed me to play with a different way of doing things. My experiments with dynamic linking used the bwBASIC as one of the tests - because it was easy to interact with it, and it was reasonably modular.
Remembering that Logo had been a popular system for teaching languages at school, I looked for some implementations that might be useful in the same capacity. UCB Logo was a quite good system, but its use of the GPL meant that it was never going to be acceptable as a general language to include with the system. It was an interesting project to port, but also not useful.
Moving to other languages, I found the 'awka' tool, which would convert an Awk script into C code. It too, produced some interesting code, but was also GPL, so wasn't going to be used; plus of course, it's dealing with Awk, which is a pretty horrid language to start with.
There were others; I have got a directory full of sources - some partially compiled, some vaguely functional, and some hardly touched beyond being extracted - for different tools which did interesting things, to try to provide a different language for people to work in. I came across a Pascal to C converter, which was quite interesting, and worth looking at. I didn't like the fact that it was GPL, but as the converter itself would be separate from other tools, it would only be the tool itself that was a problem.
I ported the tool, and added the necessary bits to make it work well within RISC OS. Throwback support was important if you're going to use the tool like the other parts of the toolchain. Similarly, filenames should be translated from their Unix form to RISC OS format if they're supplied like that - it isn't vital, but it makes the use of the tool easier in some places.
Similarly, it is very useful if the tool can run without needing any on disc
resources, so I built in the default configuration files and headers. This
is similar to how the Norcroft C compiler works, having the standard C
headers built in, and using these in preference to the versions on the disc
to speed up the compilation. I also added file dependency generation
(aka '-depend !Depend' support), which made the tools a lot
easier to use with the standard tool chain.
Finally, there was support for library of SWI interfaces, so that the Pascal code could directly call SWIs without having an interface library. This made the converter very usable for simple programs. It wasn't going to win any awards, but it worked very well for the simple things I needed it to do - converting Pascal to C.
Having got the converter ('p2c') working well, I wrote a wrapper tool ('p2cc') which would do all the necessary work to take Pascal and create objects, calling the C compiler to do the necessary work. In some respects, the wrapper was similar to the C++ tool which wrapped CFront.
The tools worked very well - it was as easy to write a simple command line tool in Pascal and compile it, as it was to write and compile a C program. A version of BASIC ('Chipmunk BASIC') was one of the example programs that came with the converter, and it ran quite well. I wrote quite a lot of test programs to exercise parts of the converter, most of which it handled reasonably well, although malformed source would confuse it sometimes.
I took one of my old programs which I had written during my A-Levels when I got bored of doing the simple exercises, and it compiled almost straight off. It was a pretty simple 6502 assembler and interpreter - you fed it some assembly source and it would assemble and run it, and even supported some of the simple I/O operations (write character, read character) from the BBC, so you could write interactive programs in 6502. It amused me a little that it would allow me to write 6502 assembler, and to have it executed by a C program built from a Pascal program, running on an ARM processor.
Some of my tools needed to be updated so that they could work with the new language. The HdrToH tool, which took ARM assembler header files which described SWIs and structures and converted them to other languages, was updated so that, in addition to C and BASIC, it could also create Pascal implementation header files. This made it a lot easier to call other SWIs from Pascal programs.
I wanted to demonstrate that writing things in Pascal wasn't only possible, but was also had a practical purpose. The easiest way to show this was to write a serious module in Pascal. I chose SoundDMA, as it was one of the more complex modules and had to deal with a lot of different areas, from interrupts through to callback functions. I created the module and, although it only handled some simple calls (not quite enough to support SoundChannels and SoundScheduler), it was working and made a quite good example of how you could write a real module in Pascal.
The whole project was stalled because I was doing other 32bit work, and I needed to get other things working, but it was left in a pretty reasonable state. I was rather pleased with the work, although I still disliked the fact that it fell under the GPL.
NettleSSH
!NettleSSH
Back in 1999, when I was working at Picsel, Alex MacFarlane-Smith sent me a copy of a little BASIC Telnet client that he had written called !ArcTalk. It was very slow, and it was a bit limited, but it worked quite well and it looked pretty reasonable. Later, he renamed the client to !Nettle and rewrote it in C. I did not get involved with it until later - other talented people were also involved in producing the very reliable client that it became.
I had previously suggested that it would be possible to integrate the SSH components from 'putty' to support SSH connections as well as Telnet. I decided to take my own advice and add in the support myself. There were a few things that needed to change to make things more modular before I could add in the code, though. For a start, the protocols were a little tied up with the other socket receive code, and some of the Telnet protocol decoding. To make things easier, I refactored all the protocol code into separate files, which were described by a dispatch structure.
Some of the protocols shared code, and some provided extra processing and output early on. For example, the SSH code would prompt for a password. I introduced the RLogin and RExec protocols at the same time (as these are very similar). Although they are insecure protocols, the were very useful for some operations - I had used RExec as part of the build in order to speed some things up.
The RLogin protocol, like SSH, required a user name, so these shared
properties to request a password. Each protocol could be invoked by a
URL request as well, for example: 'ssh:justin@buttercup'
would launch the SSH protocol, with a user name and host set up already.
Each protocol had a different icon in the hotlist - I wasn't at all imaginative for the new protocols, and gave the little machines different colours.
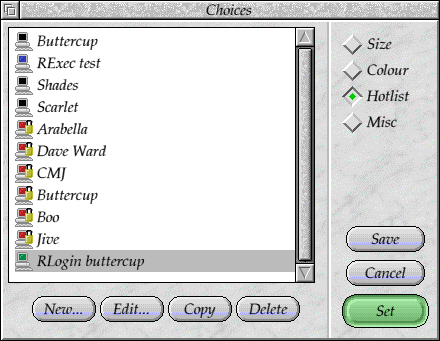
The connection window also supported including a command to run as well, so that you could run things on the remote machine directly. The command handling was used by the existing TaskWindow protocol, and the new RExec protocol as well. If the protocol did not support commands, the field would be greyed out, as you might expect.
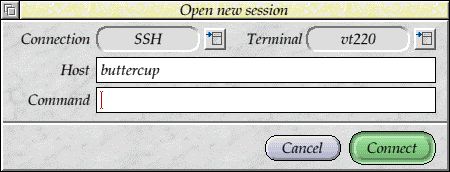
Although I had abstracted the protocols, I also wanted to split things up more. A lot of the code handled the input and output by knowing that unless the protocol was 'TaskWindow', it would use sockets. I wanted to split the handling up so that there was an extra option (which wouldn't be used often, but was still available) to select the transport. This would mean that most of the protocols would use sockets, but could also use serial or TaskWindow, which might be useful for debugging some things.
The window resize code was reworked slightly so that it allowed the protocol to be notified of the changes. This meant that as you resized the window the application running at the other end was aware of the changed size and could resize itself appropriately. I used 'pine' quite a bit for testing the resizing - it works really quite well resizing itself as the RISC OS window resizes.
Some of the little RISC OS style operations were added as well, such as adding ctrl-F2 to close the window when the session had ended - obviously it's not possible to use that whilst connected, as the application might want to use them.
The actual SSH code wasn't based directly on 'putty', but actually on the 'sshproxy' port, which Theo Markettos created a little time before. My notes say that the code was quite 'wedged in', and doesn't build quite as cleanly as the rest of !Nettle.
One of the nice things I did, and I had forgotten that I had done was to add support for Throwback to Fortify, so that you any leaks that were detected immediately popped up a message and a link in !Zap to show where the leak came from. I don't actually remember it that much, but I do have a vague recollection that it was useful in finding problems.
I was a lot happier about !NettleSSH than some of the other mini-projects. It did a great job at the time. The intention had always been to update the back end so that it supported SSH 2, but never came back to it.
Disclaimer: By submitting comments through this form you are implicitly agreeing to allow its reproduction in the diary.