Network stack
The network stack on RISC OS contains a lot of components, if you include it in its entirety. Most of the time the focus is on the core components - such as the Internet module through which most modern traffic passes. However, it communicates with quite a few other components - the drivers to send and receive data, support modules will configure things, and other modules provide the means to access various services and resources. Applications need to use other modules to perform particular tasks - filing systems like , NFS and LanManFS, provides file sharing, Resolver provides host resolution, the URL fetchers provide a means to access other remote protocols, and so on. Then there are the non-IP protocols, like AppleTalk and Econet which have to be considered as part of the stack as well.
Without any particular focus on what is being represented, I have drawn a little diagram that shows the structure of the network modules. That means that the relationships it represents are mostly of the form of 'x uses y' or 'x depends on y', rather than data or control flow. Because many cases are bidirectional, you could reverse relationships, or draw them in a different way, but I think that the diagram shows the relationships pretty well. I've tried to group components together where it makes sense to do so. However, I've omitted the connections to the Internet module for everything that uses it for pure communication, as that would complicate the graph with a spiders web of lines.
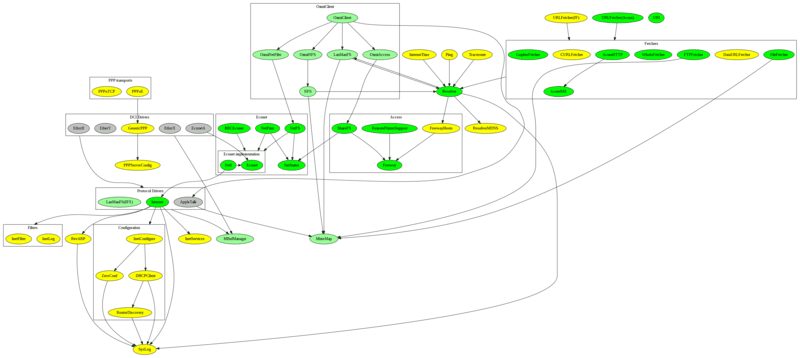
(Larger version (167K))
{kind=link}
- Green - Acorn modules
- Light Green - ANT modules supplied with Select
- Grey - Third party modules
- Yellow - My modules
LanManFS is listed twice, once within OmniClient, and once within the Protocol modules. Partly this is to simplify the diagram, and partly because the IPX protocol is only used when the module is configured to use that protocol, rather than IP - The LanManFS IPX implementation also conflicts with AppleTalk because they both want the same frames and there isn't a separate dispatcher for them. AppleTalk could also be in the OmniClient box as it is part of that system, but instead I've just represented it through an arrow to the main module in the Protocols group because it is not delivered as part of OmniClient.
There are two URLFetcher modules shown, mainly because I was intending on replacing the Acorn version with my own, but hadn't yet done so. The module's written, and pretty much works fine, but I had yet to commit to it.
The Econet section is a little amusing, as the core module is Econet which provides the API for applications to communicate using the protocol, and talks to the Econet hardware. The hardware is obsolete, so NetI performs a lot of the API functions, using an IP transport for Econet data. NetI also communicates with the Econet module to use the actual hardware, where this is present. In this way, Econet software can be used with regular Ethernet modules (or other IP transports).
In the other direction, EconetA provides an IP transport which communicates with the hardware Econet - giving Internet support to systems that only have Econet. Don't try to think about the loop that you can have if you try using all these technologies at once - sending an IP packet could go through EconetA to be sent over the Econet network, only to be captured by the NetI module and encapsulated in an IP packet and transmitted through the real Internet network (which might actually go to EconetA to be transmitted over Econet - and actually make it to the Econet hardware... or loop forever). I'm almost certain that there's a protection to prevent that happening, but its easier not to think about. It certainly confused me enough, just trying to write it down.
The URI module sits out on its own because it doesn't actually get used by anything else in the stack, if I remember rightly, and is only intended for use by the application layer. The application's use of these modules is not represented at all.
Internet
The Internet module itself was something I always enjoyed working with. Mostly. There was a persistent problem during Select 1 development which delayed release for a few weeks and wound me up no end. Essentially the machine would boot up, automatically configure a DHCP address and then crash as the machine was doing some of the subsequent setup - stuff like reading configuration from discs, configuring Freeway, initial DNS resolution of a host, or in the middle of sending packets.
At the time it happened, the BTS changes in the system were still a few years in the future - although they would have given a lot of hints as to where the problems might lie. Whilst the issue was usually in the start up, it could be triggered later if you were lucky. Also, it never happened on my main machine - only on the test system - but this was easily put down to the fact that the test system would be rebooted a few hundred times a day, and the main development system would be booted once.
Anyhow, dull-story-short... it was absolutely nothing to do with DHCP, Internet or any other part of the OS. I replaced the memory in the machine and all was well. Highly frustrating that it took so long to find - partly because it wouldn't happen all the time but when it did, it would usually warrant sufficient time investigating that it delayed a bunch of other things.
Dial up support
Early on in the development, for Select 1 I think, I made a small change to the Internet stack to provide a little more support to help diallers. The idea was that when you were not online you would want to use a failed connection to indicate that a connection to the Internet was required - providing dial on demand. The idea I had at the time, which was quite simplistic, was to trigger the dial connection whenever a failed connection was reported through 'network unreachable', 'host unreachable' or 'host down' reports. I'm pretty sure that the latter was a bad choice, but otherwise it might have been useful.
Whenever one of the above reports was received for any socket operation, a service would be issued to notify interested parties that a dial up request might be required. The change was publicised to authors, but nobody seemed to want to follow through on it. ANT had, I believe, taken a slightly different route with their PPP driver. Instead, they configured the driver to be the default route and available, even when disconnected. That way, they would receive packets which were intended for the Internet, and could trigger the dialling sequence.
These days, though, we've generally got 'always on' Internet connections, so it's not even an issue.
DHCP support
Adding the support for DHCP to the Internet module - and the various configurations that the system could be in - brought a few bugs out of the woodwork. Changing the IP address could leave some connections in a bad state, which meant that the Internet module itself could crash. This wasn't great but was relatively easy to fix. There was the obvious fun with the 'Duplicate IP address' - which we have to detect as part of DHCP configuration (and ZeroConf for that matter) - which necessitated the use of the service. The DHCP implementation in the Internet module is, as close as is possible, the same as the Pace implementation. There are a few minor differences, but nothing that should present much in the way of issues.
Amusingly, the Internet module and the DHCP module duplicated some behaviour for a while - the setting of system variables in particular. On the one hand, Internet needs to do these things to handle BootP (as DHCP is an extension of BootP, with more options available), and on the other, DHCP needs to do some of them when it is in use. Maybe the BootP implementation should have been dropped, but systems still use it, and at the time there was still the issue that STB people might use desktop RISC OS to test things, so keeping things the same was always important.
In any case, the ability for the interface to accept packets whilst still not configured left a few holes in the system which needed plugging. During DHCP (or BootP) negotiation, the interface might seem to be configured because of the way that the flags were set internally, but it wouldn't have any addresses. Some of the code paths still tried to send things - particularly UDP broadcasts - which could be confusing (and wrong) if there was nothing to respond to. Freeway caused many of these problems to appear, and there were some minor changes to the way that such things were handled.
I remember there being fixes for a number of small multicast issues that cropped up when the interface was being changed as well. I think also a multicast routing leak that happened if you changed existing addresses.
Address aliases
A number of people had requested the ability to configure
multiple addresses on a machine. I seem to recall Chris Evans
(forgive me if I'm wrong - this was all a while back) saying
that he had some systems on 1.x.y.z and others on 192.168.0.x,
and a machine between them with two network cards which would
let him access both systems. (yeah, I could be wrong, but...
it was an odd thing) Anyhow, the module had always been able
to add addresses to an interface but this was far from clear,
and generally caused issues with components that tried to
get the address of an interface (what does
SIOCGIFADDR mean for an interface that has
multiple addresses? and if you could resolve that, could you
expect that anyone else would be able to as well?).
So I created aliased interfaces - labelled as
<ifname>:<aliasnum>, for example
eh0:1. For configuration, you could create an alias
just by referencing it (although initially the alias number was
only incrementing - so you created :1, then :2, then :3, and if
you deleted :1, :2 and :3 would move down - that was fixed in
a later release) to configure an address. The link would still
remain the same, but the interface would appear differently,
making it much easier to configure. I'm not sure if anyone
actually used the ability to do this much, but it was handy for
many odd times when you just needed to be on a different
network.
To applications, these appeared as uniquely named interfaces, which meant that if they were assuming such, they continued to work. This also became easier when issuing services (eg InternetStatus_AddressChanged) which would otherwise be unable to distinguish between the different uses of interface. ZeroConf exploits this by configuring the :9 alias when it is configured. This means that should you manually configure an address for the interface, the previous address (which is link-local) can remain configured and be used without any impact.
You can still configure multiple addresses on an interface (I think), but the aliasing is also an option.
Firewall and filtering
The firewall in the Internet module has been present since Internet 5 was released. It was surprising to me that it had not been exploited by anyone. To be fair, it is a stateless firewall that only allowed very simple packet matching, but the point is that it is a firewall. With people directly connecting their RISC OS systems to the Internet (as was common with dial-up and became more so with the advent of DHCP for Broadband, rather than through a router) it was important to provide some means to configure the firewall. The InetFW was the (complicated, but functional) command to do that. I can't say that it was the easiest thing to set up, but there was documentation in the configuration file for how to set up some basic rules - I have a feeling I included filtering as the example as it was 'trivial' to access remote shares across the Internet if you had a little bit of knowledge about how the system worked (such knowledge was in PRM 5a, although you'd have to think a little to work out how to exploit it).
| Enable Firewalling (always defaults policy to 'deny')
IF "<Inet$Error>" = "" THEN InetFW -e Enable on
| Accept local (192.168.x.x) traffic on the freeway or sharefs ports
IF "<Inet$Error>" = "" THEN InetFW -e Add -n 6000 -p accept -P UDP -I -O -S 192.168.0.0/16 -D 192.168.0.0/16 49171,32771,32770
| Deny any packets on freeway or sharefs ports
IF "<Inet$Error>" = "" THEN InetFW -e Add -n 6001 -p deny -P UDP -I -O -D * 49171,32771,32770
| Default policy is 'accept'
IF "<Inet$Error>" = "" THEN InetFW -e Add -n 65534 -p accept
As well as the documentation in the configuration file, the *InetFW command also has reasonable help built in to it, through *InetFW help. It's quite nice to see that I spent some time trying to make it easier to use.
I'll talk a little more, in a later ramble about the
InetFilter module which provides
an alternative way of firewalling things (and NAT and
other things). It needed some extra information, so a few
little things were backported from FreeBSD, the IP_RECVIF
option specifically was useful here. As well as providing
the interface name as part of the options on a packet (which
is important if you're doing anything with multicast, if I'm remembering right)
it also made that information available where the filtering
took place.
Multicast
Similarly, to improve the multicast support, the DCI 4 calls were added so that drivers could provide hardware filters for multicast ranges. This could significantly reduce the processing by the driver and Internet module, by just rejecting multicast groups that we are not a member of. By default the Internet module would join the All Hosts group, and would issue notifications to the All Routers group when multicast membership was changed. Because it knows which groups it's interested in (you have to actually declare that you're interested in them), and the multicast messages are sent to a special group of Ethernet MAC addresses, you can filter out those that we're not a member of.
Transaction TCP
One of the interesting problems that some people had found with their Internet banking with Barclays Bank was that their connections never worked through RISC OS, but were fine with other systems. A few people did a bunch of investigation about the problem and found that the issue was that the 'experimental' Transaction TCP extension was in use.
This was a extension to TCP specified in RFC 1644 to try to reduce the
initial connection time by reducing the 3 way handshake which occurs
at the start of a TCP connection. It also reduced the time spent in
TIME-WAIT when connections where closed. The problem is
that the handshake prevents certain types of attacks, and the T/TCP
bypass makes it significantly easier to attack.
The option to disable the use of transaction TCP has always been
present, but was not enabled in deployed Internet systems. The switch
to disable this was just a sysctl option which could be
changed easily. The documentation for this appeared in the Acorn
distributions of the Internet resources - the one cunningly marked that
they wouldn't support the use of them in any way. An updated version of
the documentation was included in the StubsG distribution, to try to
address that issue.
The change to the configuration itself should have been applied to the Internet module, swapping its configuration around to be disabled by default. I don't remember whether I did that. There's also the possibility that the configuration could have been changed during the boot sequence. There was already some configuration for different options during boot as by default UDP checksums were disabled, and in general we want them to be on as they protect against some odd delivery problems.
I cannot see anything in the history for the Internet module. or the
Internet configuration files, so I guess it never made it to live
distribution. Hey-ho ![]() .
.
MbufManager
The MbufManager had been a constant bane for users, with MBuf exhaustion being the main complaint. That and the very low default size of the buffers. It was often talked about providing a version which might extend and contract as necessary. Whilst this was possible, it was reasonably complicated - the MbufManager was all ARM and whilst it was well structured, it did strive to be efficient for handling the buffers and this might be destroyed by adding more complexity. So I left it alone.
The usual cause of MBuf exhaustion was a bad driver. I recall that the EtherH driver (was it? that was the one with both 10BaseT and 10Base2, yes?), if not connected on start up, would default to 10Base2 mode. When packets were sent to it in this state, they would leak the MBufs they were delivered in. (at least that's my recollection - there may have been more involved than that).
However, when - in normal use - we run out of MBufs the Internet module would just drop packets, or abort the operation it was using the MBufs for. This might happen if there were a lot of outstanding retransmissions present, or fragmented packets being retained which would be reconstructed. A way to solve this was to have the module issue a 'Scavenge' service which would allow users of MBufs to free those that it was holding on to speculatively, or caching. The Internet module could respond to a 'Scavenge' by discarding some of its MBufs, where it knew that the data in them would be reobtained in a retransmission, etc.
In some extreme cases, this resulted in worse performance as retransmissions were required. However, in the majority of cases it would mean that more data would be able to be handled. For example a fragmented packet in memory, when the buffers were full, might not be able to receive a final fragment. Without scavenging, new packets coming in would be dropped and no packets could be sent, until the fragment expired. With scavenging, the oldest buffers would be discarded (possibly freeing multiple MBufs), which would usually free up sufficient MBufs to complete the fragmented packet. Of course the earlier, discarded fragment would need to be retransmitted, but it had to be when we weren't scavenging anyhow. And, of course we now have buffers available in order to store the retransmitted packet - where as the subsequent fragmented packet would essentially block the earlier one from ever being completed without scavenging.
Other modules than Internet could support scavenging, although I'm not sure if anything did.
I defined a service for Link status notifications from the DCI driver - Service_DCIDriverStatus codes 2 and 3 - which was intended for use with the DHCP and ZeroConf modules. This would say whether a cable had been connected or disconnected once the driver was sure of the state (and all users should assume 'connected'). It was a mirror of the DCI statistics flag (which it looked like nobody used) to avoid having to poll those calls in order to get the state.
A quick look now tells me that the DHCP module does appear to use this to affect the state of the connection. So does ZeroConf. Coo, that's kinda neat. Now if only it were used anywhere...
The Internet module was updated in a couple of places to add resilience - as were almost all of the network stack modules. In line with the principles of modularity, all modules had to be able to survive the death of any other module which they depended on - to whatever degree was sensible. Not only does this help with development, by making it possible to replace components arbitrarily and have the rest of the system roll on (yeah, reload the Internet module and a few moments later it's renegotiated DHCP or ZeroConf, your remote shares have reappeared and you're back in business), but also it means that the behaviour can be restored to a known state reliably - no more 'oops, didn't mean that, now I've got to reboot because module X can't be restarted safely'. This principle also helped with mix-and-match module versions, which we know that people will do, given half the chance (and may be required for testing).
There's a longer description and worked example of the restart process that the Internet stack goes through in an October 2004 diary entry.
Disclaimer: By submitting comments through this form you are implicitly agreeing to allow its reproduction in the diary.