File systems
Mostly when people talked about features they wanted from the RISC OS file systems what they really meant was features they wanted in the Filer. This made developments in this area slower, but there's a whole lot that I wanted to address within the file systems. There are a few problem areas throughout the stack, and in order to know where you are going, you have to know why.
Problems
One area that had been improved, but really needed a serious rework, was the CDFS system. The system had been improved in Select to handle a few more forms of ISO 9660 file systems, but the entire file system, being written in assembler (and very difficult to follow assembler at that), was incredibly hard to enhance and did not work very well with some systems. Not only that, but the file system itself was fixed in supporting only ISO 9660 and its variants (Joliet and RockRidge, in particular were partially supported).
Additionally, it would be very useful to provide alternate systems for
viewing the same device, for example accessing audio data and file data
through the use of separate special field (for example,
CDFS#Audio::Disc.$). This could be achieved by a switcher
module providing the filesystem layer, under which multiple systems could
handle the types of access. In essence, a CD is a block device, just like a
hard disc.
The internal implementation of CDFS is still bogged down by the SCSI interfaces - they were developed around the same time, as many CD drives were SCSI initially. Although the CDFS 3 system would have replaced many of these interfaces with a lot more sensible an API, it was abandoned back in the RISC OS 4 days as the drivers to support it just were not there. Because ATAPI CD drives became common, much of the interaction with them came about through the ADFS module, as it provided the IDE interfaces that talked to the drives. This meant that the interactions between CDFS drivers and ADFS (or other hardware drivers) were difficult to work with sometimes. Mostly they were safe, but they meant that a special CDFS driver was necessary in order to talk to the special IDE drivers that 3rd parties supplied, despite just being ATAPI devices.
DOSFS, the filesystem to access old style FAT discs had not been kept up to date, and did not even support long filenames. Other implementations had been written - Win95FS from Warm Silence Software and the freely available FATS32FS. The latter was under the LGPL so was unlikely to ever be integrated as part of the main source.
Additionally, DOSFS suffered from being an Image File System which meant that it was restricted to operations that could be done on 'files' - the disc was accessed as a file through FileSwitch. This is not ideal as it means that the File System is limited to the 231 bytes that can be accessed through those interfaces.
ADFS only handles IDE discs - 'modern' ATA discs are really only supported through the legacy modes, which makes them very limited in their operation. Improved DMA support would help as well, although the extant hardware had very poor hardware access. Not only this, but the hardware access and the IDE implementation were entwined - you could not re-target the existing ATA implementation at another piece of hardware, and this meant that all the 3rd party hardware had to perform their own disc access.
FileCore limits filesystems to a 32bit interface for sector operations. This had been extended for pre-Select versions to allow larger discs to be accessed, but was still limited to 229 sectors - which (if my maths are correct) is about 256 GB. Pace had provided an extension which allowed 64 bit sector access (again working on 512 byte sectors), but this was only stubbed at present - you could use the interface but it degraded to the old-style sector operations, so it was still had the same limitations.
In order to perform direct disc access you have to go through the providing filesystem, using SWI Filesystem_(Disc|Sector)Op (or some variant of that name). You have to go through the interface by looking it up by name, because there was no common standard ordering to the SWIs (or the naming of them).
Performing special operations on the hardware was not possible except through dedicated interfaces on the hardware, so obtaining the disc parameters (like its model and serial number) was a file system specific operation. This (and the previously mentioned disc access issue) caused every file system to have its own formatter, despite them generally being based on the same core BASIC program.
Restarting FileCore was not even destructive - sometimes it was just outright denied, depending on the systems that were running. Restarting the FileCore stack, therefore, meant that you had to reinitialise all the modules within the stack manually. This was not great as an upgrade strategy, although it was generally quite rare to need to.
With respect to disc formats, FileCore actually doesn't do as much as you might hope. Although it hands off unrecognised formats to Image File Systems, this is entwined with the file system implementation. If you have a file system that needs to use the hardware file system at a block level and needs to be larger than the Image File System provides (that is, the size of file access), you have to mess around. The Service_IdentifyDisc was not particularly friendly or usable and did not allow for partitioned regions of a disc.
FileCore's caching is a tricky beast and never really seems to live up to its potential beyond a small size. I had already shown on the A5000 that a more dedicated cache could seriously improve performance, especially when the device access times are so slow. Although it has the ability to, FileCore doesn't really deal well with read-ahead. Again, I had done experiments on this, but had mixed results because the interfaces were all blocking - reading ahead, but blocking to do so, doesn't gain you as much as you would like. It also allocates memory on a per file system basis, which means making decisions up front about how the memory is allocated - and if a filesystem is not using its cache, the memory is not available to anyone else.
FileCore offers the ability to provide only 8 discs per FileCore filesystem, and 4 of those are relegated to operating like floppy discs (and they do have different operational features - you cannot just give a hard disc a drive number of 0, unless you expect it to perform badly and to be ejectable). FileCore also performs too many jobs - it is a filesystem, switcher and cache. This might have had some efficiency once but it has the drawbacks that I have already mentioned.
There are no mechanisms for (easily) introducing synchronisation features, or wear levelling features such as the 'TRIM' commands provided for modern SSD devices. Collections of block devices for any purposes (including RAID) just are not hookable, and FileCore makes it difficult to provide any sort of gain from trying to do so without actually replacing its own interface to the filesystems (for example, inserting yourself between FileCore and ADFS - which can be done but takes care and isn't really a good plan).
FileSwitch manages all this, and has its own limitations internally. The directory caching was entirely deferred to the filesystem, which meant that - unless you were a FileCore based file system - you had to implement your own directory caching. File I/O buffering was present at a FileSwitch level, but quite limited - you can request that FileSwitch buffer up to 1024 bytes. I splutter whilst even writing the words.
FileSwitch can only handle a limited number of files at any time - 255 in
fact - due to the limitations of the interfaces used to access those file
handles, which date back to the BBC. There are a few other places beyond the
BBC interfaces where the operations are still limited to 8 bits. All the
file access (and file information) calls are based around 32 bit file sizes.
Attributes are limited to read, write, locked for this private and public
users - there are no 'owners' as such, and no way to expose such a concept.
The 'public' use is honoured by and NetFS, which maintains its own
concept of the current user. There are no 'extended attributes' which many
modern systems provide, although there are mechanisms to provide such things
through the modern IOCtl operations - but these would be system
specific.
File systems are identified both by name and by number. The filesystem number is limited to 256 file systems by certain structures and APIs, although it does not strictly control the limits as Image File Systems do not need to have a file system number.
Operations on FileSwitch are incredibly slow due to poor implementation and design of caching (at the wrong level and the wrong scale), and the requirement that files and directories be operated on by name (unless files are actively opened for writing). Files can only be opened once for writing - which simplifies the implementation, but prevents certain things from working in the way that you might expect if you have come from other systems. The lack of directory handles (which are present in NetFS) means that any file system operation which needs to validate the path to the file must validate every step along the way - which may include traversal through Image File Systems.
All filenames are assumed to be in the current locale, and are matched case insensitively. This makes it very difficult to manipulate files that come from another character set - in particular, one character set may have distinct characters, which in a second character set collate to the same thing, thus producing a one filename on disc that maps to two files. The character set is not differentiated by filesystem or device.
Symbolic Links (or hard links, or junction points, or mount points) are not implemented within the FileSwitch system, and although 3rd party LinkFS exists, it has its own issues with certain files, and does not expose its target in quite the same way as it would if it were a direct link.
The interactions within DeviceFS systems - a switcher closest to character devices on Linux, or possibly pipes - are ill defined and have caused issues in the past with USB systems.
PipeFS is something of a joke, and its usefulness is in question, never mind its limitations. Not least the fact that operations on it may not actually take effect, and it presents a very inconsistent interface to the system.
The SCSI stack isn't even provided by default with the OS, although it could be. However, the SCSI API dates from around the design of CDFS, and it shows. With many devices using the SCSI command set, now over different transports, it is very difficult to work much sanity into the system - it could be done but there are so many problems with the current implementation that some major reworking is necessary. Not to mention the fact that the SCSI module itself is assembler. I had rewritten it to match the Pace SCSI switcher specification which did a quite nice job of abstracting things and making for simpler device interactions.
Across the board the file systems are blocking unless they take action to not do so, which makes for many issues with the system waiting on I/O access. Device insertion and removal is provided for only at a FileCore level, and then really only for floppy discs (where it expects you to re-insert the disc). The concept of 'unmounting' is isolated to the FileCore filesystems.
The desktop representation of file systems as IconBar icons were handled by each provider creating a new application to handle the drive icons, each of which provided different functions which differed in order and presentation. Many times in the past I had talked about unifying these with a FilerCore module - indeed on my A5000 I had an application that did just that, replacing the ADFS, SCSIFS and NetFS icons with a single application that managed them all in a (mostly) consistent way.
Solutions?
Let us start with one of the most significant issues that hits filesystems - the speed they operate at. FileSwitch provides a level of caching, but this is high level and I want to start lower down. We want to cache blocks accessed through the block filesystems. As these are the primary way in which most (local) file systems will be implemented, they should work fast. FileCore is not especially good at it, having not been updated to handle larger or dynamic memory for some time. We want caching, and we want to make some of the other issues go away...
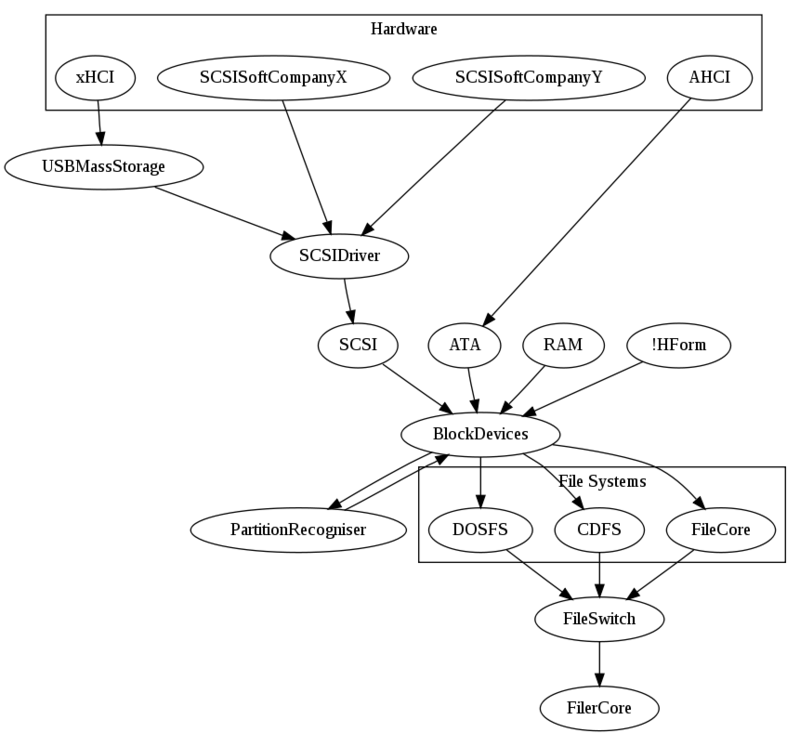
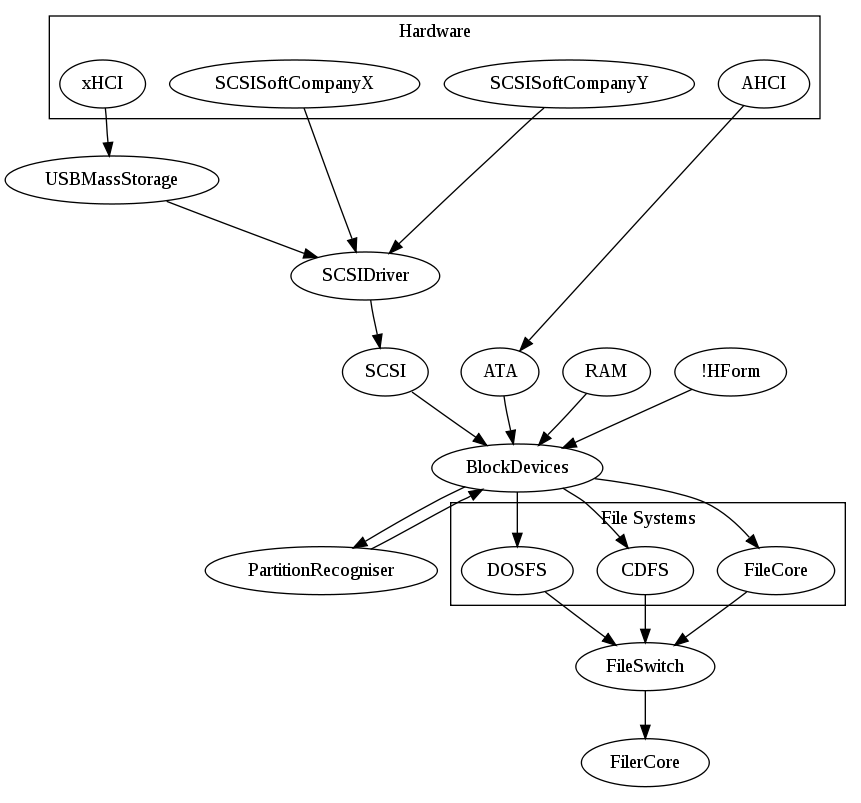
I wanted to create a new module (BlockDevice for want of a better name - I hadn't really come up with one) whose job it is to provide block access for block based filesystems. The module would handle sector sizes of 512 bytes upwards, in powers of 2. This would cater for systems like CDs which have 2K sectors, as well as the newer 4K native sector devices. Hardware drivers like ADFS (at this stage) would register themselves with the access module. The module would (also like FileCore, which I critiqued for this, but hey, this is my little fantasy world) provide both Identify operations, which would be able to perform basic operations on the device in order to access its basic information (hardware class, model, serial, identifiers, drivers, etc), and to perform hardware specific operations (power control, eject, presence, and protocol/hardware operations like retrieving raw device data, SMART, and the like).
The module would provide a blocking interface to access the devices, either cached or uncached. A future version would support non-blocking access to the device, and the interface between the hardware and the access module would be designed to allow for background operations. The current FileCore interfaces give a good idea about how that could be performed - and some of the pitfalls to avoid. As well as caching, the data could be buffered for later writing (possibly using the background interface to later be written).
By having a single module providing the buffering, we reduce the wastage from pre-allocated memory for unused filesystems and we can better manage our buffers in low memory situations. When we need to scavenge memory the system can decide which buffers are less useful based on usage, etc.
The API that the BlockDevice offered would implicitly be 64 bit, block size based, although a byte-based 128 bit interface might also be provided for ease of use - I considered this mostly because applications won't always want to handle the different block sizes themselves. Alternatively, it might be sensible to provide the interface in the form of a request and the block size the request takes, with the BlockDevice performing the necessary operations to convert the request into multiple hardware requests, or to merge into its cache as necessary. Block sizes would be declared by the hardware. Clearly it would need some thought at this level (obviously) as the best trade off between flexibility and implementation complexity needs to be found.
As devices were registered with the module, and marked as present (because devices should be able to be declared without being active in order that the identification and access to particular devices remain through similar interfaces - for example, for removable devices), it would be announced through a service for a recogniser to handle. The service would announce the type of the device, the access parameters for talking to the BlockDevice module and its basic identification information. Quite similar to the way that the current FileCore system works, but avoiding any use of filetypes and intentionally providing the information necessary for systems to work with the new BlockDevice.
New modules would pick this up - these would be 'Block Device Recogniser' modules. They would most likely actually be parts of the file system implementation themselves in many cases. They would access, through the BlockDevice interfaces the device and determine whether they could handle the filesystem format. They might also use the device information to decide if there was even any point in doing so. FileCore (the file system) would be one of these recognisers. DOSFS would be another. CDFS would be a third. Other types of filesystems might also offer themselves here. Any recogniser which supported the format would claim the service.
This is almost exactly the process that FileCore goes through, but the point is to take FileCore out of the loop - it is not the block device manager, but just a file system. Because it is just providing the services for device, there is no 'ADFS' file system any more. FileCore is providing file access for a block device, of which there can be many. In that respect, there are no disc numbers - maybe FileCore actually provides a single interface, through which multiple discs and devices are accessible. Maybe later we could consider just using mount points... I am not sure but lets continue our progression.
A partition recogniser will provide the ability to recognise a partition table and claim the block device - and then register multiple partition devices with the BlockDevice which cover the extent of each of the device partitions. There could be multiple partition recognisers - one for the common PC partitions, and another for GUID partition tables, and so on. The partition recogniser may also offer its services for creating partition tables within a block device through SWI calls.
In this way we gain the ability to partition any device in any form we like. The partition recogniser module might even include the functions necessary to create and populate a partition table on a device - with care. The registered partitions would then be subject to the same recogniser system as previously, going through the partition dispatcher. Obviously this incurs a slight dispatch penalty, but it should easily be offset by the gains of the caching. The partitioner would always issue requests using the non-caching interfaces to the underlying BlockDevice, as the device above would always be performing device operations.
Any special device operations (for example, power, eject, identify, SMART, etc) through the partitioner BlockDevice would be passed straight through to the hardware device, allowing control of the underlying device.
Block device operations such as eject and power control, which might affect the upper level systems would issue a service to request the operation, which the filesystems could accept (ensuring they flushed their buffers), or reject, depending on how they functioned. Partition recognisers acting as switching points for a single device would issue multiple services to their handlers.
Device removal notifications from the lower block level would be notified through a service, and each recogniser would discard its data about the device. Partition recognisers would merely need to claim that their 'device' had been removed, which would result in the BlockDevice issuing a removals for them.
Software RAID implementations could merge BlockDevices by examination of the format, or through a stored configuration and use of the identity blocks. It must, therefore, be possible to examine the devices which have been registered but not claimed, as these would be the devices that RAID implementations would care most about as devices were attached. Alternatively, the RAID implementation could be provided as a recogniser which identifies a collection of devices as they appear and claims the devices - but offers no block device until sufficient number of the devices have become available for use.
Hardware RAID implementations would be able to provide other functions by providing special hardware drivers to talk to the hardware in whatever ways were necessary - providing replacements for SMART and the different special operations as necessary, some of which (like 'eject' have less meaning on such a system).
From this, the CDFS drivers pretty much go away. In their place one of two forms of device access will be used - either direct SCSI operations, through a SCSI block device, or an ATAPI transport for SCSI commands.
SCSI block devices would present a single interface to the BlockDevice module, and therefore be accessed in the same way as other forms of block devices. Eventually, hardware ATA devices would stop using the ADFS module, and a proficient ATA module would be created. This ATA module would talk the ATA command set - mostly performing switching actions to hardware drivers which would register with it.
So with both SCSI and ATA systems you would have the same pattern - hardware drivers register with the switcher module (SCSI/ATA), these modules register the block devices for the hardware connected to them (and remember that any SCSI or ATA hardware may actually be providing multiple actual devices) to the BlockDevice system, declaring their hardware class. Applications could talk to the devices through BlockDevice (or the BlockDevice registered on behalf of the partition recognisers, which would then talk to the underlying BlockDevice) using either the block access APIs or through the special device operations to talk directly to the SCSI/ATA layer.
Although Image File Systems could still exist, it would be quite possible to present a bare file on a filesystem through a Image File System interface which registered itself as a BlockDevice - thus allowing such devices to be accessed as if they were plain discs. On other systems, such mount points are through 'loop back' devices.
Filesystem formatters, for example !HForm, would no longer need to be tied to a particular filesystem, because they only needed to talk to the BlockDevice layer, and then request that it recognise the block device once formatted. Similarly, disc format maintenance tools (such as fsck) would be able to operate on the device more easily - obviously the BlockDevices interfaces would need to include explicit synchronisation calls for the filesystems to honour in order to keep the system valid at the point they were run. It would not be unreasonable for the file system itself to offer the option of formatting the device (much as FileCore does now, but extended for the block device interface).
FileSwitch associates drives by name, which is useful for many types of devices, such as physical discs and remote storage. FileCore presently provides device numbers, for which fixed discs and removable discs are differentiated by number; 0-3 are removable, 4-7 are fixed. With the use of recognised BlockDevices, the drive numbers would not be obvious, although they could be exposed as part of the interface alongside the SMART information. The device numbers, together with the controller would allow physical devices to be located - which becomes more of an issue when you have large numbers of discs!
A new interface would be needed for FileSwitch to enumerate device names. This would allow components to list the devices which were possibly available for use, along with their type. For example, a remote filesystem might offer both the filesystems that were already mounted, and those that were unmounted but known to exist. This could incorporate some of the details which OmniClient currently manages for its filesystems.
More specifically, rather than just listing devices that might be mounted, the enumeration should offer an indication of methods of connecting to the devices. As well as being able to say that there were remote devices available, the enumeration might also indicate that logging on to a given server with credentials would offer more devices. OmniClient dealt with some of these issues, so it would be foolish to ignore its collected wisdom on the topic.
A new module, possibly FilerCore, would provide the desktop IconBar icons based on the devices that were present. As devices appeared, so would icons, and if a disc was accessible through it, it would be populated. Or maybe not - the idea of putting all the devices on to the IconBar is a little restrictive and wasteful. The other work on IconBar abstraction would help in this area (see the ramble about Future directions for the Desktop).
Instead of the desktop Free application needing to have handlers for block filesystems, it would be able to handle all the systems that were registered.
This restructuring of the block devices in the file system stack would:
- Take away the focus and reliance from FileCore.
- Introduce centralised and extensible caching.
- Make it simpler to implement block filesystems.
- Give a consistent interface to access the block devices for both block access and special operations.
- Provide consistent formatters and management tools.
- Automatic recognition of new devices.
- Remove the need for a lot of extra hardware vendor support beyond interfaces to their devices.
Of course, this is a quite radical restructuring, and it wouldn't all happen at once. Parts would be able to be changed incrementally. Moving the caching out of FileCore for a start would give a good start on the interfaces and improve performance if done right. This would also ensure that existing hardware that talked to FileCore continued to work. Of course, in order to make things work properly there needs to be a cut off, but if FileCore can be acting as a legacy provider, merely proxying for the hardware that registered with it to the BlockDevices module, that would make the transition significantly easier.
CDFS on the other hand does not have the same problem - everything goes through the CDFSdriver, so making it register against BlockDevice on the hardware's behalf would make most of the drivers work. To benefit properly, they would obviously need to be upgraded to more direct providers, but that is something that would take quite a bit of time.
A quick sketch of the structure might look something like this...
{kind=link}
This would address the block filesystems, but there are many other filesystems which would not be touched by such a change - the archive filesystems and obviously the non-block-based network filesystems. These systems are equally poorly supported, and moreover these systems tend to have greater latency when accessing data, and thus have to either cache more data, or perform more operations.
For these systems (and for the FileCore as well, because it would also benefit) we would introduce the ability to provide larger file buffering and caching in FileSwitch itself, and the ability to cache directory operations. These could be added directly to FileSwitch, or as an extension module which is used for certain operations. To be useful, the filesystems they are caching for must really declare what type of caching and buffering is appropriate.
For example, a file buffer might find that writing out data slowly is useful, but keeping a large local buffer is very useful. Obviously the flush operations (and file close) would cause the operations to block until the buffers had drained (or maybe not - file synchronisation might be an optional operation). Buffering and caching are closely related, so it is likely that the two would be implemented in the same code base.
My primary concern with placing the functionality within FileSwitch itself (rather than having the feature provided by a separate module that registers the functionality) is that FileSwitch is a lot of assembler which is quite complicated. Identifying the buffer management code, and abstracting it cleanly into an interface that can be provided externally gives a couple of benefits - a) the cache/buffer provider can be written in a sane language (which for someone other than me might mean assembler), b) the interface is more structured and better thought out, c) the interface is independently testable, d) the entire system can be replaced, possibly on the fly.
There is obviously complexity in providing such an interface, but by closely defining the API this can be controlled. FileSwitch would provide a fallback in the case that no provider was available - to directly access the registered filesystem. Caching files could give huge benefits even for local filesystems, especially as memory sizes increase. Buffering data allows any slower systems to write out data as necessary and with larger buffers, the data can be written out in larger chunks.
Providing a cached enumeration interface would significantly improve the performance of FileSwitch in general - the system at present is very slow at performing many operations because of enumeration and file metadata retrieval costs. To generally improve the performance of such operations, the NetFS-like operations to open a directory and obtain a handle to it should be used more widely. This sort of operation is used in other systems, and by merely passing around a file handle instead of having to parse a full filename every time it is required, we can improve many operations. I would not expect this to happen immediately, but there is an improvement to be had by merely hashing the paths for lookup and referencing the resulting handles, rather than performing a full search.
The benefits of the enumeration system would be more significant on network filesystems. I am envisaging a more advanced enumeration interface at the filesystem interface. At present requests for file information, and for enumeration of directories, are passed on to the filesystem without much processing - different forms of directory or file requests may end up at the filesystem, and result in more or less work by the filesystem.
For example, if the application calls the 'enumerate filenames in directory' API, the similar entry point will be called within the filesystem. This may mean that the filesystem actually has to read all the details for files in the directory from the server, and then reduce this just to the filenames, and then hold on to the results in order that if they request file information on a file it may be returned from their cache. This is done on a per filesystem basis. Moving the caching out from the filesystem means that the filesystem can get on with what it is good at. Obviously there will be validity periods set on all the data returned, so that stale cache data is not retained and so that an expiry can be placed on the cache in a useful way. For the filesystem, though, this means that it will instead be able to do the 'most appropriate operation for the request'.
Instead of returning just the filenames requested, the filesystem could return all file attributes, because that was easier for it to obtain. The cache system would use that information to fulfill the request - and subsequent requests would be faster because the data was already cached. The cache system would be intelligent enough to know to discard lesser data when requests were made. For example, if a filesystem returned all attributes and the cache had the filename data, it would replace the former with the latter. The cache should also be able to handle individual file requests, so that if an application kept requesting the filetype of a file it would return it from either the cache of the file's data, or from the previous enumeration of the directory if the data was available.
The focus of the caching system should be to maximise the use of local
data, without being wasteful. Some filesystems might request that no data
be cached, which would reduce operations to the older form, but that is the way
that things go - they may need it, for example PipeFS or a dynamic content filesystem
(think of /proc or similar on Unix systems).
Using a handle system for enumerations would address the race condition currently present when enumerations are spread over file operations. The principle is that the handle could uniquely identify an enumeration context without being affected by other changes. This is purely a legacy from the system considering it single process, and should be addressed.
It might be more complicated to get right, but if implemented outside of FileSwitch it could be tested independently and replaced if found to be poor (and of course the modularity means that should a third party wish to sell a replacement, they could do so).
Many operations in FileSwitch run through the system variable system in order to make working directories, libraries, 'user root directories' and previously selected directories work. The system variables are looked up when any of those names are needed. This change was made (if I remember rightly) back in RISC OS 3, and meant that just changing the system variable would affect the system, or you could use them in other commands. The RISC OS 4 system variable changes, which were retained for Select, improved their speed, but they are still not great.
Because these are read regularly, they should be managed by FileSwitch. They can still be system variables, but by becoming code variables they could be 'looked up' by just loading a value from a workspace location, rather than being extracted each time. The variables would be substantially the same, with a slight difference that an empty string would replace an unset string. I believe that this would help with improving the speed of the early processing of operations (prior to the cached data being needed).
This is a completely independent change which does not need any other of the changes I have suggested to be made. That makes it an easy win if you were looking to improve performance. Obviously it is important to benchmark and profile to ensure that this really is the case, but it was my belief that it couldn't possibly be worse (except if the implementation was really screwed up).
This said, getting rid of filesystem specific library directory and User
Root Directories might eliminate certain confusion and potential problems.
They serve very little purpose in the modern system, and may only confuse, especially
where the Run$Path exists and is used normally. It is possible
that File$Path should also be abandoned, as it is highly
unlikely that anyone is using it well, and I would expect that the vast
majority of developers (never mind users) would find their software or systems
broken or work differently should it be set. Run$Path should
also be a candidate for being moved to a code variable and pre-parsed at the
point it is set, rather than on use.
As mentioned previously, FileSwitch would find that it could easily get more filesystems registered with it if the restructured block devices implementation was put forward. Greater numbers of filesystems mean that the core filesystem numbering is worthless. Aside from allowing a simple filtering based on filesystem, this does not give much benefit. Actually, the number of locations that a filesystem needs to be identified is quite low - although FileSwitch itself does use them to identify legacy filesystems which need special quirks applying to them.
It is possible that abandoning the filesystem names could be done, but I
don't see it myself. Whilst it might be possible to introduce a root
filesystem, and to attach filesystems within this, I do not think it would
give a great benefit. In particular it might mean a huge rework of the
UpCallV interfaces were necessary.
On the other hand, such notifications would probably need to change anyhow -
because the file size limitations need to be addressed, and the change
notifications that UpCallV provides would change with it.
Essentially, a new 64bit file access interface should be provided. I have
heard talk by others that the 231 problems in the current API
should be addressed, to double the size of files but this seems like a
fruitless exercise. The only thing you would gain out of it (which is not
insubstantial) would be the understanding of the interfaces and their
limitations, and maybe a few fixes in corner cases.
Because applications use negative numbers to indicate exceptional cases in the file offsets, or for other purposes - or just may not themselves have the correct unsigned file handling - improvements in this area of FileSwitch and the filesystems would mean that application authors would need to check/update their code. Just to be able to access files of up to 4 GB. If you have a need to access files over 2 GB, you probably have an equal requirement to handle files over 4 GB, so requiring an update to application code to handle the gain, and then requiring updates again to get more than 4 GB when a 64 bit interface is implemented is just going to be annoying.
So... go straight to the 64 bit interface - the extant interface is not expected to work beyond 231, and that is the end of that story. The new 64 bit interfaces would need to be provided across the board, but it also offers an opportunity to rationalise some interfaces. This might fit nicely with work for the caching interfaces. The old interfaces will remain, but at least the new ones can be designed better, and not just hacks on the old BBC interfaces (albeit they still retain the spirit). The old interfaces would need to work when presented with large content, for example a 4GB file would need to report sensibly if you enumerated it with a 32bit interface. Of course, if you are going through a caching layer such things can be fixed at that level, albeit pushing complexity to that point would mean it would need to be duplicated if it was on the far side of the external module interface. Ideally the reduction would happen in FileSwitch after retrieving data from the cache.
There are a whole host of problems with extending the interfaces, from having wider data sizes being returned when enumerating, through to the effects of writing data up at such large sizes - and that is before we consider the filesystem effects of having such huge devices. FileCore cannot cope with the sorts of discs that would have lots of 4 GB files on it (and I am not sure it internally handles things at that size very well). (As an aside, neither does the NTFS on Ubuntu when trying to write huge files - it begins to crawl beyond about 35 GB).
Filesystems should, initially, be assumed to operate in the current UTF-8 (for the purposes of filename matching), but a new flag should be introduced which indicates that the filename convention returned from the filesystem itself is in a particular alphabet (and is encouraged to be UTF-8). This would introduce complexity to some to add support, but many systems might merely mark themselves as returning in Latin 1 or even plain ASCII (which there isn't an alphabet for, but Latin 1 might suffice there). This would bring FileSwitch to a consistent level, and the caching system could be constructed such that all operations were reduced to UTF-8 internally. This would pave the way for making the system alphabet UTF-8.
An 'easy' improvement would be to increase the number of handles available through the filesystem interfaces. Not only would this give a good review of the interfaces that currently exist, but it would also highlight those interfaces that would not survive the future larger filesystem operations (and any which could be deprecated, etc). In many cases there are operations which work just fine with wider numbers of file handles.
As the handles are system-wide, there is no limitation on the way that handles are reused, so it might be useful to allocate handles in a round robin fashion so that any application using handles incorrectly is less likely to hit an earlier handle. This would probably mean a change in the allocation ordering, so bundling it together with using incrementing handles would help. At present the handles are allocated descending from 255 for purely historic reasons.
As we would like to keep most of the operations within 8 bits, but still allow for a greater number of handles, the most sensible solution is to change the allocation to be increasing from 1, instead. An interface had already been added for enumerating file handles, so knowing the implementation order was no longer necessary for any applications. Obviously, updating the interfaces to allow for more than 256 handles could come later.
It is pretty rare to run out of handles, but the benefit isn't so much in the actual extension of the handles, but in the fact that the change covers many of the interfaces and allows the old ones to be identified and deprecated and new interfaces (for larger file operations and the like) to be created early on, so that they can be used prior to their being functionally available. Probably it would mean that a bunch of the SWI OS_Byte calls would be deprecated (and could be moved to LegacyBBC if they had not been already), which I never consider a bad thing.
On a number of occasions I had considered the addition of metadata APIs for filesystems and files. For filesystems it might allow more information to be provided on the filesystem beyond its name, size and space used. Similarly, formatting parameters and features could be very useful to know. At present it is necessary to do a few special things in order to work out what type of FileCore system is being accessed, or its parameters. This could be eased by having a special tagged interface for reading such information - and maybe for setting parameters as well, eg overriding character sets, or forcing a particular compatibility mode could be useful.
I am not sure whether it would be a filesystem attribute, or just a core feature, but I had always considered that it might be useful to be able to change mounted discs to be read only - it is only possible to declare that the filesystem is read only at present (for example CDFS and ResourceFS), whereas some discs may themselves be read only. It might be because they have been locked, or because they have been declared unsafe to write to because of inconsistencies, but it is very useful to prevent writes to a disc.
For files, the extra metadata ('Extended Attributes' as they are known in other systems) could contain other information about the files - maybe as a native feature, but could also be useful for exposing attributes set on non-native filesystems which have no direct comparison in RISC OS APIs.
The file attributes wouldn't be an easy one to add, as there would initially be no support in any filesystem, but it could be very useful for the network filesystems. NetFS could be considered to have some extra attributes, as the file creation time is stored independently of the load and exec addresses.
Outside of FileSwitch, some of the other filesystems could do with being updated. CDFS has already been mentioned as a mess. In many respects it would be better to rewrite it. It causes such pain in being written in awkward assembler, that it might be better to rewrite. It's possible that the CDFS 3 implementation might be a good starting point - I'm not certain, given my poor memory of that area (I haven't looked at it since we started RISCOS Ltd).
Knowing what CDFS should be able to handle would be a good start, as at present it is mostly just trying to handle the things that people complained didn't work, plus the obvious deficiencies. If it was to stick to ISO 9660, then there is less complexity involved, but would be more restrictive as other file formats appear.
DOSFS, at the very least, needed to be updated to support long filenames. I had a quick hack at it, at one point, and didn't get very far - it needs more work and that would probably have been done. LanManFS as well, should have been updated to the longer name requests. I had done some of that work as well, before moving on to other things - it, too, was not particularly advanced.
NFS was still stuck in a bad place, with its RISC OS
file access managed through special files, if I remember rightly.
ImageNFS was a very good implementation and worked very well almost
all the time. In particular NFS did not support the file
type extensions using ',xxx' on the end of the filename, which
reduced its usefulness. That (and the ',llllllll,eeeeeeee'
load/exec address format) should have been a priority, so that the types
were consistent.
RAMFS was fine as it stood, but every so often I remember Paul asking if I could create an extensible RAM filesystem so that we did not have a fixed disc for storing files. I never really felt that this was as useful - it is more work, and there were a few third-party filesystems which performed this job. It wasn't worth the extra work, so I probably wouldn't have spent any time on it.
Every so often people asked about changing the native file system format away from FileCore. I had no objection to doing so, except for the time it would take to develop such a thing. As usual there were suggestions of using other open source components to do this, which is always possible, but as GPL wasn't usable, and LGPL was probably not great for the use within such a core component, that left the BSD, MIT and other free licenses - still quite a few filesystems, but you still have to integrate it. I am sure it would have been re-investigated had it seemed like it would be a more viable option than continuing to maintain FileCore - and obviously others would be freer to implement such a thing if the BlockDevices system was implemented.
People had often commented that it would mean changing the directory separator and introducing file extensions if we used a Unix or Windows style filesystem. This generally bemused me, because the representation within the filesystem does not generally require any particular directory separator - you just use your native directory separator to separate the logical hierarchy. Whilst I had, previously, added calls to read the directory separator from FileSwitch, they probably were not likely to be used by anything ever. Too small a user base to change such things, with very little benefit.
I have mentioned, in passing FilerCore. Despite the confusing name, we could not think of a better name. The principle was simple enough, and came from independent thoughts that we had all bought to the table at RISCOS Ltd. I remember David Thomas and I discussing, recently, how that idea had not got off the ground and we really should have done more about it. Anyhow, it should have been done. Rather than every file system author providing their own implementation of an IconBar filer icon, they would declare themselves to FilerCore which would do the job.
As I have mentioned, this could be unified with changes to FileSwitch registering of filesystems. Each File System could provide a list of its features and attributes, together with a default icon which should be used. The FilerCore would take care of everything else. Not only would this simplify the filesystem for the author, but it would also ensure that the presentation of filesystems was consistent - and could be changed centrally.
Disclaimer: By submitting comments through this form you are implicitly agreeing to allow its reproduction in the diary.